

Voxel51 تطلق تقييم العيّنات لكشف إخفاقات نماذج الذكاء الصناعي
أعلنت شركة Voxel51 عن تقديم طبقة جديدة في منظومة MLOps تُعرف باسم تقييم العيّنات، وتهدف إلى كشف إخفاقات خفية في نماذج التعلم الآلي لا تظهر في مؤشرات الأداء الإجمالية، مما يساعد الفرق على اتخاذ قرارات نشر أكثر دقة وثقة.
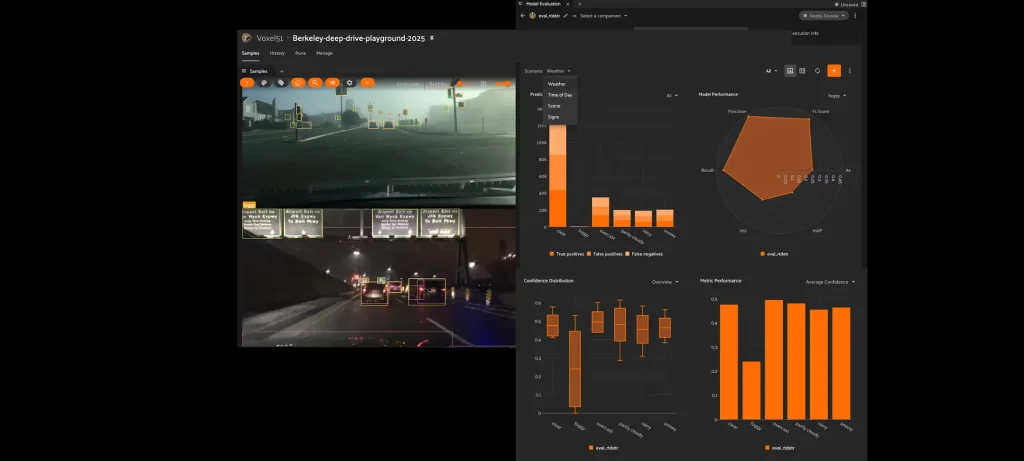
تفاصيل الخبر
تعاني العديد من فرق الذكاء الاصطناعي من فجوة حقيقية بين تدريب النماذج ونشرها في بيئات الإنتاج، حيث تبدو النتائج ممتازة على الورق، لكنها تفشل في سيناريوهات حقيقية وحساسة.
- قدمت Voxel51 مفهوم Sample-Level Evaluation كطبقة مفقودة بين تتبع التجارب والنشر الفعلي للنماذج.
- يتيح هذا النهج فهم أداء النموذج على مستوى كل عيّنة بدلاً من الاكتفاء بمؤشرات مثل الدقة الإجمالية أو متوسط الخسارة.
- يكشف التقييم التفصيلي أسباب فشل نماذج ذات دقة مرتفعة في سيناريوهات حرجة مثل الإضاءة المنخفضة أو الأجسام الصغيرة.
- يوضح لماذا قد يتفوق نموذج بدقة أقل إجمالاً في بيئة الإنتاج مقارنة بنموذج آخر يتصدر مؤشرات الأداء التقليدية.
- يساعد على اكتشاف أخطاء البيانات نفسها، مثل العينات المصنفة بشكل خاطئ أو التحيز في مجموعات التدريب.
- تعتمد Voxel51 في ذلك على أداة FiftyOne، التي تُمكّن من فحص التنبؤات بصرياً وتحليل الإخفاقات بشكل عملي.
الأهداف المستقبلية
تسعى Voxel51 من خلال هذا التوجه إلى إعادة تعريف مفهوم جاهزية النماذج للنشر في أنظمة MLOps الحديثة.
- تقليل الحوادث في بيئات الإنتاج الناتجة عن إخفاقات غير متوقعة للنماذج.
- رفع مستوى الثقة عند نشر نماذج الذكاء الاصطناعي في تطبيقات حساسة.
- تمكين الفرق من تحسين البيانات والنماذج بناءً على فهم عميق لأنماط الفشل.
- استكمال منظومة MLOps بطبقة تقييم حقيقية تركز على السلوك الفعلي للنموذج.
- الانتقال من النشر القائم على الأرقام إلى النشر القائم على الفهم والثقة.
في الختام، يمثل تقييم العيّنات خطوة مهمة نحو نضج حقيقي في عالم MLOps، حيث لا يكفي أن تبدو النماذج جيدة في التقارير، بل يجب فهم سلوكها بدقة قبل الوثوق بها في الواقع العملي.





