Qwen3-ASR: جيل جديد بالتعرف على الكلام متعدد اللغات
يدعم نموذج Qwen3-ASR التعرف على الأصوات بدقة عالية، مع ميزة التعامل مع الغناء، اللهجات المختلفة، والنصوص الموجهة.

تفاصيل الخبر
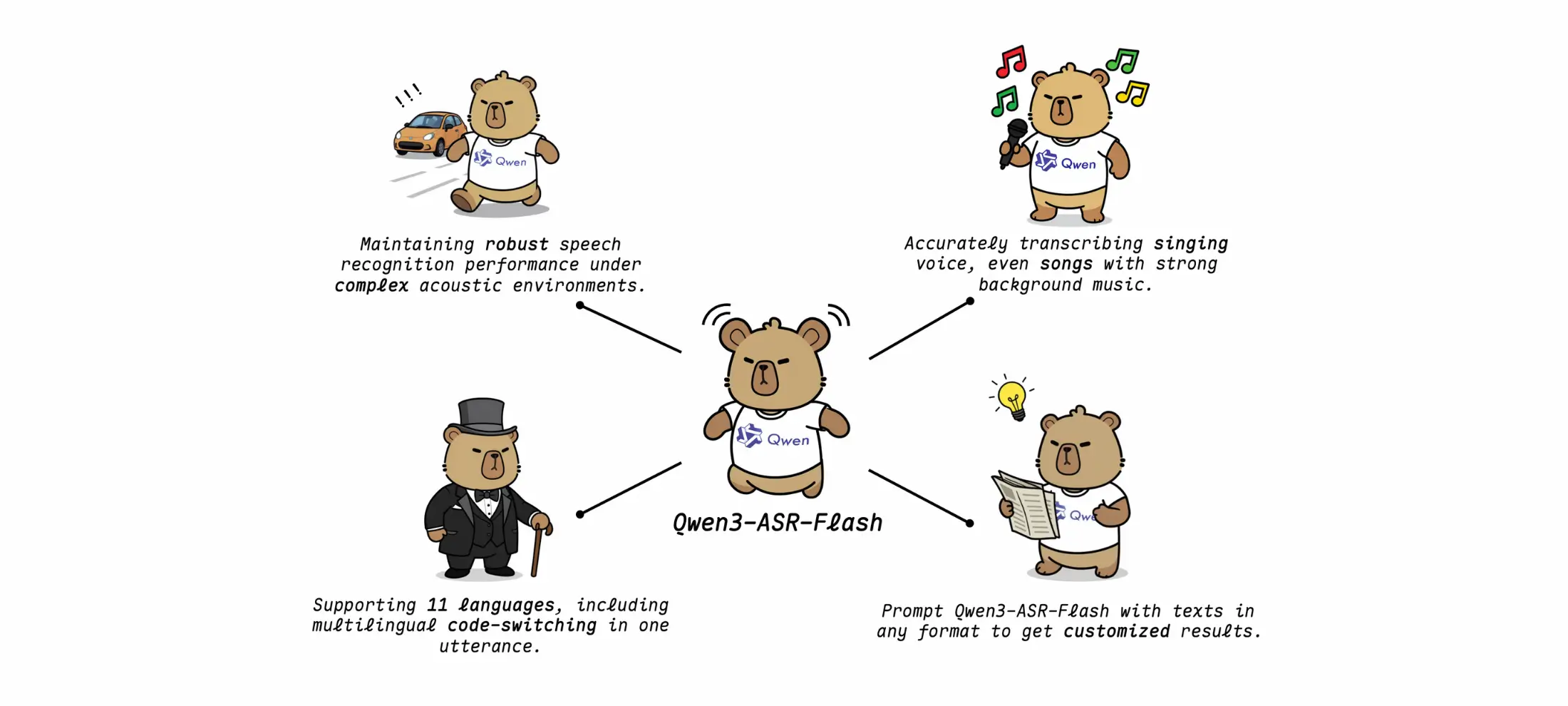
أعلنت علي بابا عن إطلاق نموذج Qwen3-ASR-Flash المبني على Qwen3-Omni وبيانات ضخمة من الصوتيات متعددة الوسائط. النموذج يتميز بقدرة قوية على التعرف على الكلام حتى في البيئات الصوتية المعقدة، مع دعم 11 لغة رئيسية.
أبرز المزايا:
- دقة رائدة: تفوق على نماذج منافسة في اختبارات اللغة الصينية، الإنجليزية، وتسع لغات أخرى.
- التعرف على الغناء: نسخ الأغاني حتى مع وجود موسيقى خلفية.
- الانحياز السياقي المرن: إمكانية إدخال كلمات مفتاحية أو نصوص طويلة لتخصيص النتائج.
- تعدد اللغات واللهجات: يدعم الصينية بلهجاتها (الماندرين، الكانتونية، الوو وغيرها)، الإنجليزية بلكناتها المتنوعة، إضافة إلى الفرنسية، الألمانية، الروسية، الإيطالية، الإسبانية، البرتغالية، اليابانية، الكورية، والعربية.
- التعرف على اللغة ورفض الضوضاء: يميز بدقة بين 11 لغة مدعومة ويرفض المقاطع غير الكلامية مثل الضوضاء أو الصمت.
- قوة الأداء: يضمن نتائج عالية حتى في ظروف صوتية صعبة أو مع أنماط نصية معقدة.
الأهداف المستقبلية
تسعى علي بابا من خلال هذا النموذج إلى تحقيق مجموعة من الأهداف الاستراتيجية في المرحلة المقبلة:
- تطوير دقة النموذج بشكل مستمر لمواكبة تطور أدوات الذكاء الاصطناعي في التعليم والتطبيقات العملية.
- تحسين الأداء في التعليم عن بعد من خلال تسهيل نسخ المحاضرات متعددة اللغات.
- توسيع نطاق دعم اللهجات لتشمل مزيدًا من التنوع اللغوي.
- إدماج النموذج في أنظمة الاتصالات، التعليم، والبث المباشر لتوفير وصول أسهل للمحتوى الصوتي.
يمثل Qwen3-ASR خطوة متقدمة في عالم تقنيات التعرف على الكلام، حيث يجمع بين الدقة، المرونة، ودعم لغات ولهجات متعددة، ما يجعله أداة استراتيجية للمستقبل.