

OpenAI تُطلق HealthBench لتقييم أداء الذكاء الصطناعي بالصحة
كشفت OpenAI عن أداة HealthBench لتقييم فعالية وسلامة نماذج الذكاء الاصطناعي في المحادثات الصحية، بمشاركة 262 طبيبًا لتحديد معايير جديدة في القطاع الطبي.
تفاصيل الخبر
في خطوة نوعية تهدف لتعزيز الثقة في تطبيقات الذكاء الاصطناعي في الرعاية الصحية، أطلقت OpenAI منصة HealthBench، وهي معيار تقييم جديد يعتمد على تفاعل واقعي بين المستخدمين والنماذج الذكية.
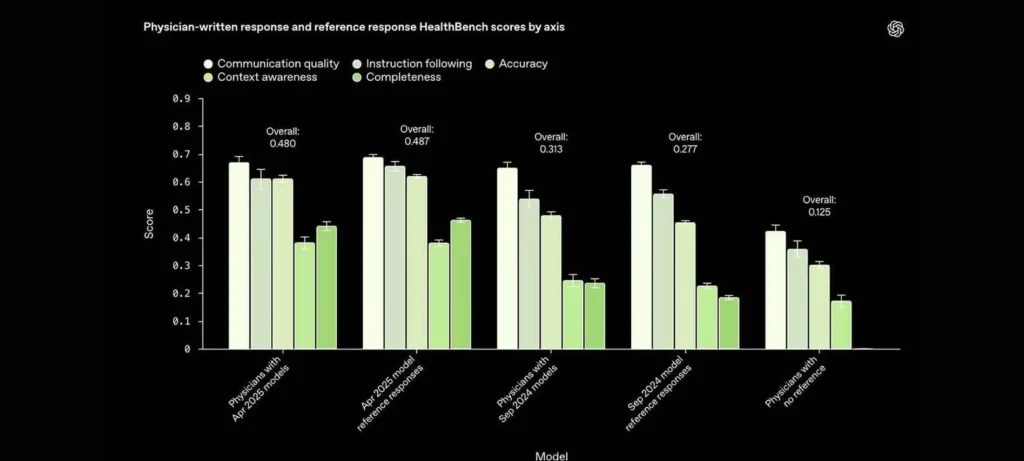
- تم تطوير HealthBench بالتعاون مع 262 طبيبًا لتوفير تقييم دقيق وعملي.
- يغطي التقييم مواضيع متعددة مثل التحويلات الطارئة والصحة العالمية.
- يركز أيضًا على سلوكيات محددة مثل الدقة وجودة التواصل.
- النموذج o3 من OpenAI حقق 60% في التقييم، مقارنة بـ GPT-3.5 Turbo الذي حصل على 16% فقط.
- نماذج صغيرة مثل GPT-4.1 Nano تفوقت على الأجيال السابقة، وكانت أقل تكلفة بـ 25 مرة.
- تم فتح مصدر البيانات والتقييم، والذي يشمل 5000 محادثة صحية متعددة الجولات بين المستخدمين والنماذج.
الأهداف المستقبلية
تهدف OpenAI من خلال HealthBench إلى تحقيق ما يلي:
- تأسيس معيار عالمي موثوق لتقييم أداء نماذج الذكاء الاصطناعي في الرعاية الصحية.
- تحسين سلامة وفعالية النماذج المستخدمة في المحادثات الطبية عبر مقاييس يحددها الأطباء.
- دعم قرارات النشر والاستخدام من خلال بيانات حقيقية وتقييمات متعمقة.
- تعزيز دور النماذج الصغيرة وفتح المجال لاستخدامها بتكلفة أقل في تطبيقات الرعاية الصحية.
- تمكين الباحثين والمطورين من الوصول إلى بيانات مفتوحة لتحسين النماذج المستقبلية.
يمثل HealthBench نقلة نوعية في تقييم الذكاء الاصطناعي الطبي، ويؤكد التزام OpenAI بالمعايير الأخلاقية والعلمية لتطوير تقنيات آمنة وفعّالة في خدمة صحة الإنسان.





