

OpenAI تكشف عن مقياس SWE-Lancer لتقييم أداء الذكاء الاصطناعي
أعلنت OpenAI عن SWE-Lancer، مقياس جديد لقياس أداء الذكاء الاصطناعي في المهام البرمجية الحقيقية على منصات العمل الحر، مع جوائز مالية تصل إلى مليون دولار.
تفاصيل الخبر
مؤخراً، أطلقت OpenAI مقياسًا جديدًا يسمى “SWE-Lancer” لقياس أداء نماذج الذكاء الاصطناعي في البرمجة عبر مهام حقيقية على منصات العمل الحر مثل Upwork:
- مهام حقيقية: يتضمن المقياس أكثر من 1,400 مهمة برمجية حقيقية، بدءًا من إصلاحات الأخطاء البسيطة وصولاً إلى تنفيذ ميزات متقدمة.
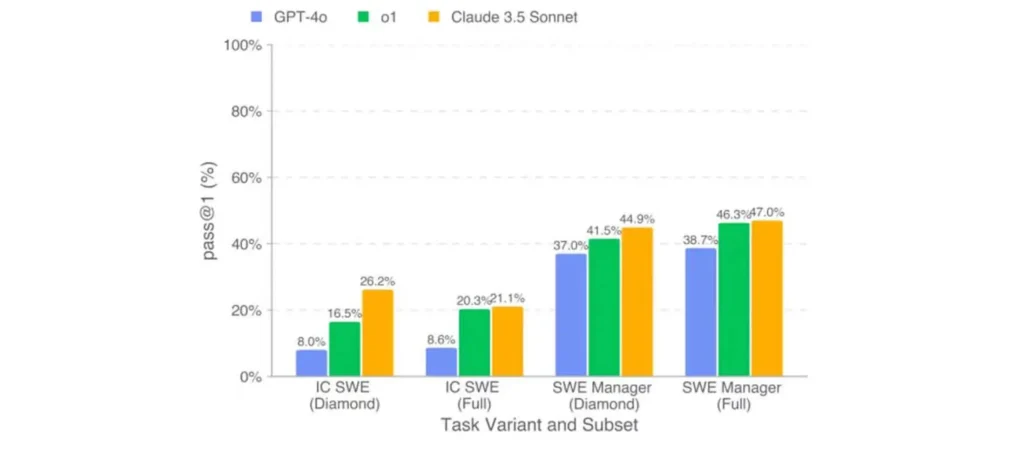
- التقييم الشامل: يقيّم المقياس أداء النماذج في البرمجة واتخاذ قرارات فنية وإدارية، حيث يتعين على الذكاء الاصطناعي كتابة الكود واختيار الحلول الهندسية.
- المكافآت المالية: يتم قياس النجاح من خلال المبلغ المالي الذي يمكن للنموذج “كسبه” عند إتمام المهام بشكل صحيح، مع وجود جائزة إجمالية قدرها مليون دولار.
- أفضل أداء: من بين النماذج التي اختبرت، حصل “Claude 3.5 Sonnet” على أفضل أداء، حيث حل نصف المهام وجمع 400 ألف دولار من الجائزة الإجمالية.
الأهداف المستقبلية
تهدف OpenAI إلى:
- زيادة التحدي: سيتم تصميم المقاييس المستقبلية لتقييم النماذج المتقدمة بشكل أفضل، مع الحفاظ على التوازن بين التحدي الواقعي والقيمة المالية.
- التحول في العمل: يمثل هذا المقياس خطوة هامة نحو تحديد دور الذكاء الاصطناعي في العمل البرمجي المتقدم، خاصة مع التطور السريع في قدرات النماذج.
من خلال مقياس “SWE-Lancer”، توفر OpenAI طريقة مبتكرة لاختبار قدرة النماذج على أداء مهام حقيقية في مجال البرمجة، مما يعزز من أهمية الذكاء الاصطناعي في العمل المستقبلي للمطورين.خاتمة





