

OpenAI تختبر الذكاء الاصطناعي أمام البشر في 44 مهنة
أطلقت OpenAI معيارًا جديدًا باسم GDPval لقياس مدى قدرة نماذج الذكاء الاصطناعي على مجاراة جودة عمل البشر في بيئات مهنية حقيقية، عبر 44 وظيفة مختلفة.
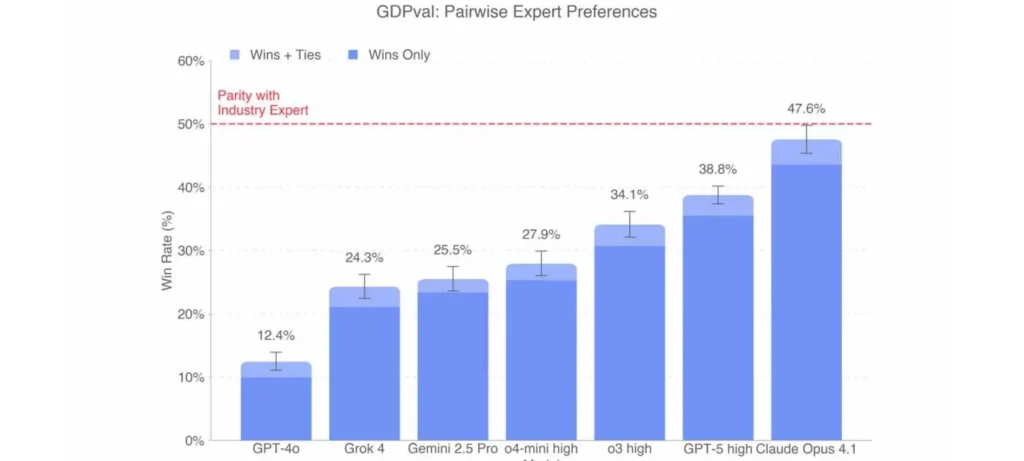
تفاصيل تجربة OpenAI
المعيار اعتمد على مهام عملية صممها خبراء محترفون بمتوسط خبرة 14 عامًا في 9 قطاعات اقتصادية رئيسية مثل الرعاية الصحية والتمويل.
- تم تقييم 1,320 مهمة موزعة على المهن المختارة.
- نموذج Claude Opus 4.1 حقق أعلى النتائج بنسبة فوز بلغت 47.6% وتفوق في المهام المتعلقة بالعروض المرئية.
- بينما تفوّق GPT-5 في جانب الدقة التقنية.
- النتائج أظهرت أن الأداء تضاعف ثلاث مرات تقريبًا بين GPT-4o و GPT-5 خلال 15 شهرًا فقط.
ماذا تعني هذه النتائج؟
رغم أن العناوين تتحدث عن استبدال البشر بالذكاء الاصطناعي، إلا أن الاختبارات تكشف أن النماذج الحالية وصلت للتو إلى مستوى مقارب للبشر في بعض المهام، وليست بديلاً كاملاً بعد. لكن بالنظر إلى سرعة التطور، قد نشهد خلال أشهر قليلة قفزات جديدة تجعل الفجوة تتسع لصالح الذكاء الاصطناعي.
معيار GDPval يمثل خطوة مهمة لفهم حدود الذكاء الاصطناعي في سوق العمل، فهو يكشف عن قدراته الحالية ويضع مقياسًا واضحًا لمتابعة تقدمه المستقبلي. وبينما لا يزال الإنسان متفوقًا في كثير من الجوانب، الاتجاه العام يشير إلى أن المعادلة قد تتغير قريبًا جدًا.





