MIT تطور نماذج اللغة التكرارية (RLMs) لتوسيع سياق LLMs
قدمت MIT تقنية جديدة تُعرف باسم نماذج اللغة التكرارية (Recursive Language Models – RLMs)، تسمح لنماذج الذكاء الاصطناعي بمعالجة سياقات طويلة جداً عن طريق استدعاء نفسها بشكل متكرر داخلياً.
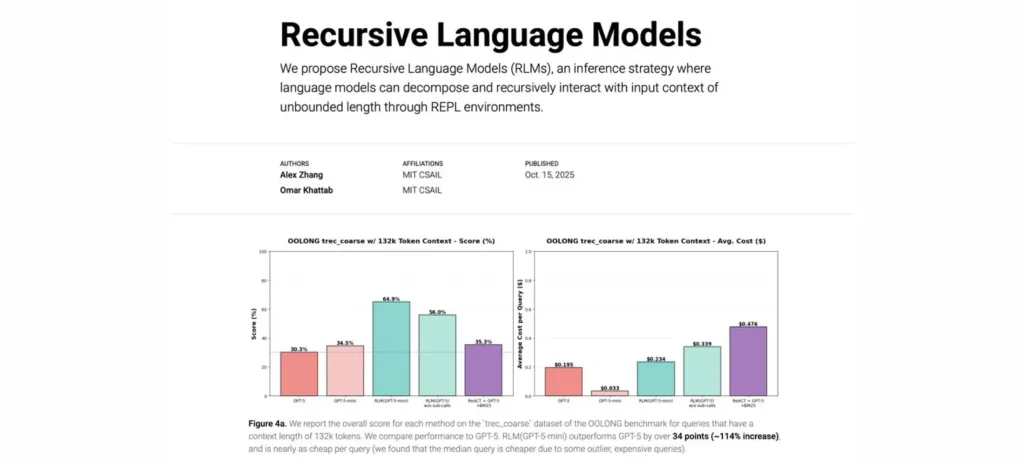
أظهرت التجارب الأولية أن GPT-5 mini المزود بـRLMs يتفوق على GPT-5 بنسبة أكثر من 110% على اختبارات السياق الطويل، مع تكلفة أقل لكل استعلام، مما يفتح آفاقاً جديدة للتعامل مع نصوص ضخمة بدون فقدان الأداء.
تفاصيل الخبر
تعتمد RLMs على فكرة السماح للنموذج “الجذر” بالتفاعل مع بيئة سياقية تشبه Jupyter REPL:
- يتم وضع مدخلات المستخدم في متغير Python، ويستطيع النموذج كتابة تعليمات وتحليل مخرجات كل خطوة.
- يمكن للنموذج استدعاء نسخ منه بشكل تكراري لمعالجة أجزاء مختلفة من السياق الطويل دون الحاجة لقراءة المحتوى كله دفعة واحدة.
- هذه الطريقة تتجاوز أي تقنيات تقسيم النصوص التقليدية، إذ يقرر النموذج بنفسه أفضل طريقة لاستكشاف وتحليل السياق.
- تهدف RLMs لحل مشكلة context rot، وهي تدهور أداء النماذج عند التعامل مع سياقات طويلة جداً أو تاريخ محادثات ممتد.
النتائج الأولية على المعايير الجديدة:
- على معيار OOLONG لسياقات 132k–263k توكن، تفوقت RLMs مع GPT-5-mini على GPT-5 بنسبة 114% و49% على التوالي، مع تكلفة أقل.
- على معيار BrowseComp-Plus (BC+)، تمكنت RLMs من التعامل مع أكثر من 10 مليون توكن دون فقدان الأداء، متجاوزة استراتيجيات مثل ReAct + retriever loops.
الأهداف المستقبلية
تقنية RLMs تهدف إلى:
- تمكين النماذج اللغوية الكبيرة من التعامل مع نصوص وسياقات ضخمة وطويلة جداً بشكل فعال.
- الحفاظ على أداء النماذج عند زيادة طول السياق إلى مستويات لم تكن ممكنة سابقاً.
- دعم الاستعلامات المعقدة متعددة الخطوات (multi-hop) على مستندات متعددة.
- توفير بيئة برمجية تفاعلية للنماذج تساعدها على تجزئة ومعالجة المعلومات الكبيرة بشكل تلقائي.
- فتح آفاق لتطبيقات جديدة في التعليم، البحث العلمي، وتحليل البيانات الضخمة.
تمثل نماذج اللغة التكرارية خطوة مهمة نحو رفع قدرات نماذج الذكاء الاصطناعي على التعامل مع سياقات طويلة ومعقدة، مع الحفاظ على الكفاءة والدقة، ما يمهد الطريق لعصر جديد من التطبيقات الذكية التي تتطلب تحليل معلومات ضخمة ومتعددة الأبعاد.