

MiMo-7B: نموذج شاومي الصغير يتفوّق على عمالقة الذكاء الصطناعي
شاومي تفاجئ العالم بإطلاق MiMo-7B، نموذج ذكاء اصطناعي مدمج يتفوّق في الرياضيات والبرمجة على نماذج أضخم مثل o1-mini من OpenAI.
تفاصيل الخبر
كشفت شاومي عن نموذجها الجديد MiMo-7B، الذي يبرهن أن الكفاءة والذكاء ليستا دائمًا مرهونة بحجم النموذج. فقد استطاع هذا النموذج المدمج، المكوّن من 7 مليار معلمة فقط، التفوق على نماذج أكبر في اختبارات الاستدلال الرياضي وتوليد الشيفرات.
- تم تطوير MiMo-7B بالكامل داخل فريق Big Model Core Team التابع لشاومي.
- تم تدريبه على حوالي 25 تريليون رمز تشمل نصوصًا طبيعية، تعليمات برمجية، ومهام استدلال صناعية.
- اعتمد الفريق استراتيجية ثلاثية المراحل في التدريب، شملت تجزيء المسائل المعقدة إلى أهداف فرعية.
- خضع النموذج لاحقًا إلى تحسين بالتعلم المعزز (Reinforcement Learning)، ما حسّن نتائجه بشكل كبير.
- في اختبار MiniF2F للاستدلال الرياضي، حقق النموذج نسبة نجاح بلغت 88.9%.
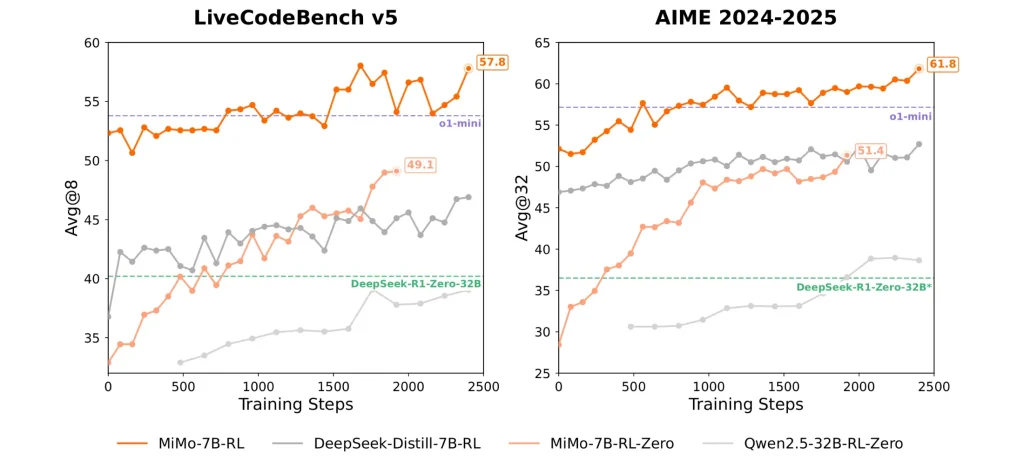
- في اختبار LiveCodeBench، سجّل 57.8%، متفوقًا على Alibaba QwQ-32B وأقرب لمستوى Qwen3-30B.
- سجّل 55.4 نقطة في اختبار AIME 2025، متجاوزًا o1-mini بـ 4.7 نقطة.
شاومي لم تكتفِ بالإعلان، بل قامت بفتح النموذج بالكامل للجمهور على GitHub وHugging Face، بما يشمل نقاط التحقق وتقارير فنية مفصلة.
الأهداف المستقبلية
تخطط شاومي لمواصلة تطوير MiMo-7B بإضافات استراتيجية تهدف لتعزيز قدرته واستقلاليته:
- زيادة طول السياق لاستيعاب مهام أكبر وأكثر تعقيدًا.
- دعم لغات متعددة بشكل أعمق لتحسين الاستخدام العالمي.
- دمج مباشر مع أجهزة شاومي لتعزيز تطبيقات الذكاء الاصطناعي على الحافة.
- تحسين تقنيات التحقق المنطقي وتعزيز فهم النموذج للسياقات البرمجية الدقيقة.
نموذج MiMo-7B من شاومي يعلن بداية مرحلة جديدة في الذكاء الاصطناعي، حيث لم تعد القوة تقاس فقط بعدد المعلمات، بل بالكفاءة والابتكار في التصميم والتدريب.





![FLUX.1 Kontext [dev]: محرّك تحرير الصور بذكاء مفتوح المصدر](https://3arabi.ai/wp-content/uploads/2025/06/Black-Forest-Labs-768x346.webp)