Microsoft تطلق 3 نماذج ذكاء اصطناعي للنص والصوت والصور
أعلنت شركة Microsoft عن إطلاق ثلاثة نماذج ذكاء اصطناعي جديدة ضمن عائلة MAI، قادرة على توليد النصوص والصوت والصور بسرعة وكفاءة عالية، مع إتاحتها عبر منصة Microsoft Foundry لتطوير التطبيقات.
تفاصيل الخبر
كشفت Microsoft عن نماذج متقدمة تستهدف المطورين والشركات، وتشمل:
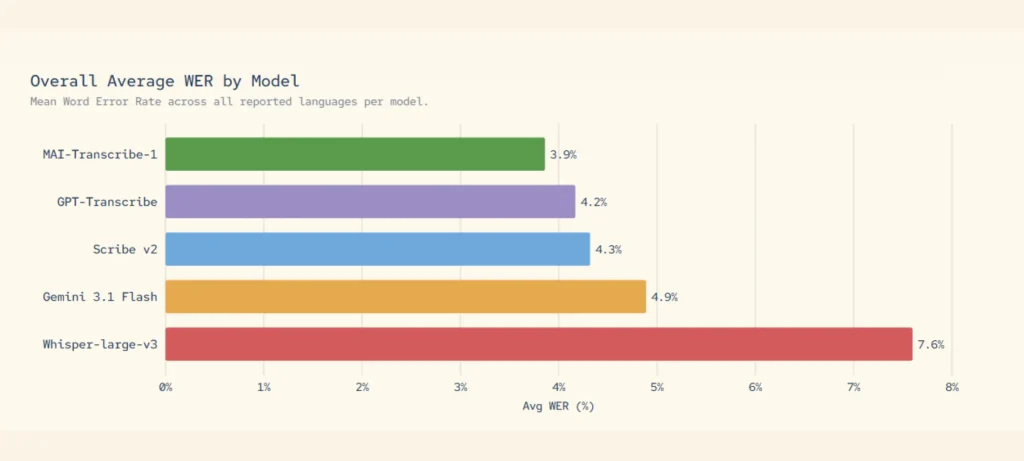
- نموذج MAI-Transcribe-1 لتحويل الكلام إلى نص، يدعم 25 لغة ويعمل بسرعة أعلى بـ2.5 مرة مقارنة بخدمات Azure Fast، مع دقة عالية حتى في البيئات المعقدة.
- نموذج MAI-Voice-1 لتوليد الصوت الطبيعي، قادر على إنتاج 60 ثانية صوتية خلال ثانية واحدة، مع إمكانية إنشاء صوت مخصص من عينة قصيرة.
- نموذج MAI-Image-2 لتوليد الصور (وأيضاً دعم الفيديو)، يتميز بسرعة مضاعفة مقارنة بالإصدارات السابقة وجودة عالية تناسب المصممين وصناع المحتوى.
- إتاحة النماذج عبر منصة Microsoft Foundry، مع توفر نماذج الصوت والنص أيضاً في MAI Playground.
- تقديم أسعار تنافسية، حيث يبدأ استخدام النماذج من مستويات منخفضة مقارنة بمقدمي الخدمات السحابية الآخرين.
- اعتماد هذه النماذج بالفعل في منتجات مثل Copilot وBing وPowerPoint، مع استخدامات واسعة في المجالات الإبداعية.
الأهداف والتوجهات المستقبلية
تسعى مايكروسوفت من خلال هذه النماذج إلى تحقيق مجموعة من الأهداف:
- تمكين المطورين من بناء تطبيقات تعتمد على الذكاء الاصطناعي بسهولة وسرعة أكبر.
- تحسين تجربة المستخدم عبر دمج الصوت والنص والصور في تطبيقات موحدة.
- تعزيز المنافسة في سوق نماذج الذكاء الاصطناعي من حيث الأداء والتكلفة.
- دعم الاستخدام الآمن والمسؤول عبر أدوات حوكمة مدمجة داخل Foundry.
- توسيع استخدام هذه النماذج داخل منتجات مايكروسوفت وخدماتها مستقبلاً.
تعكس هذه الخطوة تسارع مايكروسوفت في تطوير نماذج متعددة الوسائط، ما يعزز مكانتها في سباق الذكاء الاصطناعي ويوفر أدوات قوية للشركات والمطورين لبناء تجارب رقمية أكثر تطوراً.