METR: GPT-5.2 يتفوق على البشر في مهام هندسية معقدة
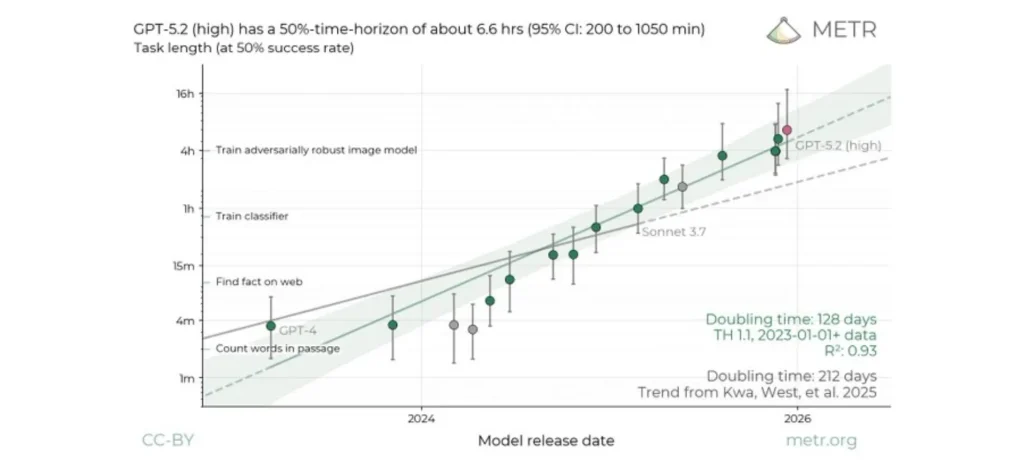
أصدرت شركة METR لتقييم الذكاء الاصطناعي تحليلًا جديدًا أظهر أن GPT-5.2 بنمط التفكير العالي قادر على أداء مهام برمجية معقدة تتطلب من مهندس بشري أكثر من 6 ساعات، مما يعكس تقدمه الملحوظ في حل المشكلات.
تفاصيل الخبر
كشفت شركة METR عن نتائج تقييم GPT-5.2، مشيرة إلى قدرة النموذج على التعامل مع مجموعة واسعة من المهام البرمجية والهندسية المعقدة بكفاءة استثنائية.
- نموذج GPT-5.2 بنمط التفكير
highيحقق ما يسمى بـ “أفق الزمن” المتوسط حوالي 6.6 ساعات، وهو تقدير أعلى سجلته METR لأي نموذج حتى الآن. - فترة الثقة 95% تتراوح بين 3 ساعات و20 دقيقة وحتى 17 ساعة و30 دقيقة للمهام نفسها.
- يشمل التقييم مجموعة موسعة من المهام البرمجية، مما يعكس قدرة النموذج على حل مشكلات معقدة ومتنوعة مقارنة بالمعايير البشرية.
- التقرير يظهر تفوق GPT-5.2 في الأداء على البشر في مواقف تحتاج تفكيرًا وتحليلًا معمقًا.
وفقًا لـ METR، توفر هذه القياسات مؤشرًا مهمًا لقوة النماذج الحديثة في أداء مهام تستغرق وقتًا طويلًا للبشر، مما يعزز مكانة GPT-5.2 كأداة فعّالة للمهندسين والمطورين.
الأهداف المستقبلية
من خلال هذه النتائج، تسعى METR ومطورو GPT إلى:
- تمكين المهندسين من إنجاز مهام برمجية معقدة بشكل أسرع وأكثر دقة.
- تعزيز قدرة نماذج الذكاء الاصطناعي على التعامل مع المشكلات طويلة المدى والمعقدة.
- توفير أدوات مساعدة للفرق التقنية لتسريع تطوير البرمجيات وتحسين جودة الحلول.
- اختبار نماذج مستقبلية لتحقيق أفق زمني أطول وأداء أعلى على المهام الهندسية.
- دعم البحوث المستمرة في قياس كفاءة وموثوقية الذكاء الاصطناعي في سيناريوهات العالم الواقعي.
تؤكد نتائج METR أن GPT-5.2 يمثل نقلة نوعية في قدرات الذكاء الاصطناعي، حيث يمكنه إتمام مهام تتطلب ساعات من العمل البشري، ما يعزز دوره كأداة قوية للمهندسين والمطورين.