

Meta FAIR تطلق DINOv3 نموذج رؤية بدون الحاجة لبيانات معنونة
أعلنت Meta عن إطلاق DINOv3، نموذج رؤية متقدم يعتمد على التعلم الذاتي (SSL)، قادر على تحقيق أداء متميز في مهام الرؤية دون الحاجة لبيانات معنونة، مما يفتح آفاقًا جديدة في الذكاء الاصطناعي.
تفاصيل الخبر
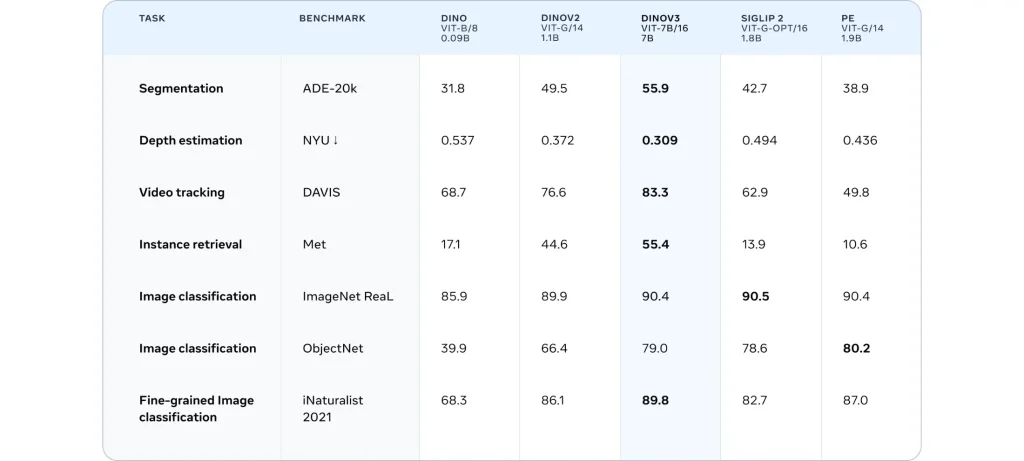
أطلقت Meta مؤخرًا نموذج DINOv3، الذي يمثل تقدمًا كبيرًا في مجال الرؤية الحاسوبية باستخدام التعلم الذاتي. تم تدريب النموذج على أكثر من 1.7 مليار صورة، ويتميز بقدرته على استخراج ميزات بصرية عالية الجودة دون الحاجة لبيانات معنونة.
- تعلم ذاتي بدون تسميات: DINOv3 يعتمد على تقنيات التعلم الذاتي لاستخراج ميزات بصرية، مما يلغي الحاجة للبيانات المعنونة.
- أداء متميز في المهام المتعددة: حقق النموذج أداءً متفوقًا في مهام مثل تصنيف الصور، تقسيم الصور، اكتشاف الأجسام، واسترجاع الصور.
- نموذج متعدد الأحجام: يتوفر DINOv3 بأحجام تتراوح من 21 مليون إلى 7 مليار معلمة، مما يتيح استخدامه في بيئات مختلفة.
- ترخيص مفتوح المصدر: تم توفير النموذج والرمز المصدري على GitHub وHugging Face، مما يسهل الوصول إليه واستخدامه.
الأهداف المستقبلية
تسعى Meta إلى تعزيز استخدام DINOv3 في مجالات متعددة، بما في ذلك:
- تحسين دقة الرؤية: مواصلة تحسين دقة النموذج في المهام المختلفة.
- توسيع التطبيقات: توسيع استخدام النموذج في مجالات مثل الرصد البيئي، الرعاية الصحية، والقيادة الذاتية.
- التعاون المجتمعي: تعزيز التعاون مع المجتمع البحثي لتطوير النموذج وتقديم حلول مبتكرة.
يمثل DINOv3 خطوة متقدمة في مجال الرؤية الحاسوبية باستخدام التعلم الذاتي، ويُتوقع أن يُحدث تأثيرًا كبيرًا في التطبيقات المستقبلية.





