
FDM-1 نموذج يتعلم استخدام الكمبيوتر من الفيديو
كشفت شركة Standard Intelligence عن نموذج جديد يحمل اسم FDM-1، قادر على تعلم تنفيذ مهام الكمبيوتر من خلال مشاهدة مقاطع الفيديو، في خطوة قد تعيد تعريف طريقة تدريب وكلاء الذكاء الاصطناعي على استخدام الأنظمة الرقمية.
تفاصيل الخبر
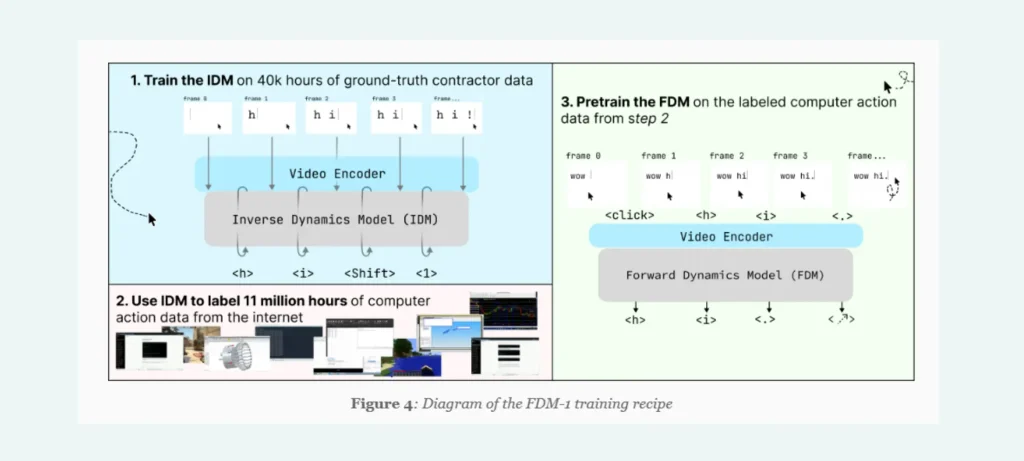
يعتمد FDM-1 على فكرة “نموذج أفعال الكمبيوتر”، حيث لا يكتفي بتحليل الصورة المعروضة على الشاشة، بل يحاول عكس هندسة الأفعال التي أدت إلى ظهور كل إطار بصري، ما يمنحه فهماً عملياً لطريقة تشغيل البرامج.
- تم تدريب النموذج على نحو 11 مليون ساعة من تسجيلات الشاشات، وهو رقم يفوق أكبر مجموعة بيانات مفتوحة بحوالي 550 ألف مرة.
- يستطيع متابعة ما يقارب ساعتين من النشاط المتواصل على الشاشة دفعة واحدة.
- يعالج سياقاً بصرياً أكبر بـ50 مرة مقارنةً بالنماذج الحالية.
- شملت العروض التجريبية إنشاء تروس ميكانيكية داخل برنامج Blender.
- أظهر قدرة على اكتشاف أخطاء برمجية داخل بيئات تطوير.
- تم اختباره في قيادة سيارة حقيقية داخل San Francisco باستخدام مفاتيح الأسهم وبيانات مباشرة، مع أقل من ساعة بيانات تدريبية مخصصة للمهمة.
الفكرة الأساسية وراء النموذج تشبه ما حدث مع النماذج اللغوية الكبيرة التي تعلمت الكتابة من نصوص الإنترنت، لكن هنا يتم استغلال الفيديو لتعليم النموذج كيفية “العمل” فعلياً على الكمبيوتر، وليس فقط وصف ما يراه.
الأهداف المستقبلية
تسعى Standard Intelligence إلى توسيع نطاق هذا النهج FDM-1 ليشمل عدداً أكبر من المهام المعقدة التي تعتمد على التفاعل البشري مع الأنظمة الرقمية.
- تمكين الوكلاء من أداء مهام احترافية في التصميم والهندسة.
- أتمتة عمليات تصحيح الأخطاء البرمجية واختبار الأنظمة.
- تحسين قدرة النموذج على الاحتفاظ بالسياق طويل المدى.
- توسيع استخدام الفيديو كمصدر بيانات تدريبي شامل لتعليم المهارات العملية.
إذا نجح هذا الاتجاه، فقد نشهد جيلاً جديداً من وكلاء الذكاء الاصطناعي القادرين على تعلم أي مهمة رقمية تقريباً بمجرد مشاهدتها، ما يرفع سقف إمكانات الأتمتة إلى مستوى غير مسبوق ويغير طبيعة التفاعل بين الإنسان والآلة.





