

GeneBench-Pro من OpenAI لاختبار الذكاء الصناعي بعلم الأحياء
كشفت شركة OpenAI عن معيار GeneBench-Pro الجديد لقياس قدرة نماذج الذكاء الاصطناعي على اتخاذ قرارات علمية معقدة في مجال الأحياء الحاسوبية. ورغم تحقيق GPT-5.6 Sol أفضل أداء بين نماذج الشركة، فإنه نجح في حل 28.7% فقط من المشكلات، ما يؤكد أن الذكاء الاصطناعي لا يزال بعيدًا عن مستوى الخبراء في الأبحاث العلمية المتقدمة.
تفاصيل الخبر
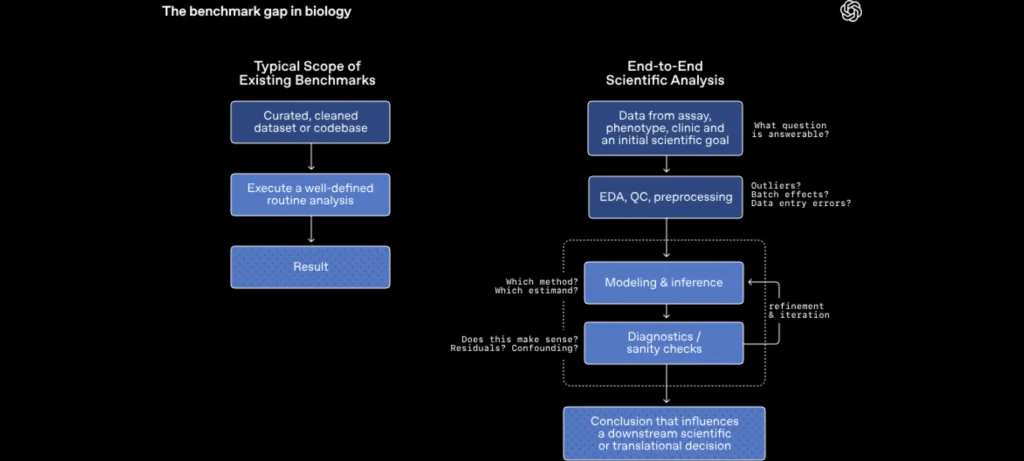
يعد GeneBench-Pro معيارًا بحثيًا جديدًا صممته OpenAI لقياس مهارات التفكير العلمي، وليس مجرد تنفيذ التعليمات أو استرجاع المعلومات، حيث يختبر قدرة النماذج على التعامل مع بيانات بيولوجية معقدة وغامضة مشابهة لما يواجهه الباحثون في الواقع.
وتشمل أبرز تفاصيل الإعلان ما يلي:
- يضم GeneBench-Pro ما مجموعه 129 مسألة بحثية تغطي 10 مجالات رئيسية و21 مجالًا فرعيًا في الأحياء الحاسوبية.
- تشمل الاختبارات تخصصات مثل علم الجينوم، وعلم الوراثة السكانية، والبروتيوميات، وعلم الأورام الجيني، والطب الانتقالي، والتشخيصات السريرية.
- تعتمد جميع المسائل على بيانات واقعية ومعقدة تتطلب من النموذج اختيار أسلوب التحليل المناسب، وتعديل الفرضيات، واتخاذ قرارات علمية أثناء سير العمل.
- استخدمت OpenAI بيانات تركيبية (Synthetic Data) تعرف مسبقًا بنيتها السببية، مما يسمح بتقييم النتائج بدقة بعيدًا عن التحيز أو اختلاف أساليب التحليل.
- راجع 82 سؤالًا من أصل 129 خبراء خارجيون، من بينهم أساتذة جامعات، وباحثون، وطلاب دكتوراه ومتخصصون في علم الوراثة.
- حقق نموذج GPT-5.6 Sol معدل نجاح بلغ 28.7% عند أعلى مستوى من التفكير، وارتفع إلى 31.5% عند استخدام وضع Pro.
- للمقارنة، سجل GPT-5.5 نسبة 12.0% فقط في وضع التفكير القياسي، بينما حقق 20.5% في وضع Pro.
- جاء Opus 4.8 في صدارة النماذج المنافسة بنسبة 16.0%، متفوقًا على نماذج مثل Gemini 3.5 Flash وGLM 5.2 وDeepSeek V4 Pro.
- تشير OpenAI إلى أن أفضل النماذج الحالية ما زالت تعجز عن حل أكثر من ثلثي المسائل، وهو ما يبرز صعوبة المهام التي يتضمنها المعيار.
- تقدر الشركة أن الخبير البشري يحتاج إلى ما بين 20 و40 ساعة لحل المسألة الواحدة، في حين تستطيع النماذج تنفيذ التحليل بتكلفة لا تتجاوز بضعة دولارات، رغم انخفاض مستوى الاعتمادية مقارنة بالخبراء.
الأهداف المستقبلية
تهدف OpenAI من خلال GeneBench-Pro إلى توفير معيار أكثر واقعية لقياس تطور الذكاء الاصطناعي في المجالات العلمية، مع التركيز على جودة اتخاذ القرار وليس سرعة تنفيذ الأوامر فقط.
ومن أبرز الأهداف المستقبلية للمشروع:
- تطوير معايير تقيس مهارات التفكير العلمي والاستدلال في البيئات البحثية الواقعية.
- تحسين قدرة النماذج على التعامل مع البيانات الغامضة واتخاذ قرارات تحليلية دقيقة.
- مساعدة الباحثين في تسريع تحليل البيانات البيولوجية واكتشاف الفرضيات الجديدة.
- دعم أبحاث الجينوم والطب الدقيق عبر أدوات ذكاء اصطناعي أكثر موثوقية.
- توفير جزء من المعيار كمصدر مفتوح للباحثين من خلال منصة Hugging Face، مع إتاحة مجموعة فرعية للتقييم المستقل بواسطة Artificial Analysis.
- تقليل الوقت اللازم لتحليل البيانات البيولوجية المعقدة مع الحفاظ على جودة النتائج.
- تسريع اكتشاف العلاجات الجديدة من خلال تحسين قدرة النماذج على تفسير الأدلة الوراثية والسريرية.
تكشف نتائج GeneBench-Pro أن الذكاء الاصطناعي يحقق تقدمًا ملحوظًا في الاستدلال العلمي، لكنه لا يزال بعيدًا عن الاعتماد الكامل في الأبحاث المتقدمة. ومع ذلك، فإن انخفاض تكلفة التحليل وسرعته يجعلان هذه النماذج أدوات واعدة لمساعدة الباحثين وتسريع الاكتشافات العلمية، وليس استبدال الخبراء في الوقت الحالي.





