

جوجل تطلق نموذج Gemini 3.1 Flash للصوت الذكي
أعلنت Google عن إطلاق نموذج جديد لتحويل النص إلى صوت يحمل اسم Gemini 3.1 Flash، في خطوة تهدف إلى تقديم تجربة صوتية أكثر واقعية وتحكماً، مع قدرات متقدمة في التعبير والنبرة.
تفاصيل الخبر
كشفت Google عن Gemini 3.1 Flash TTS كأحدث نماذجها في مجال تحويل النصوص إلى كلام، مع تحسينات كبيرة في جودة الصوت والتحكم في طريقة الإلقاء.
- دعم “Audio Tags” للتحكم في النبرة، السرعة، واللهجة بدقة عالية
- إمكانية توجيه الأداء الصوتي باستخدام أوامر نصية مباشرة
- دعم أكثر من 70 لغة لتجربة عالمية شاملة
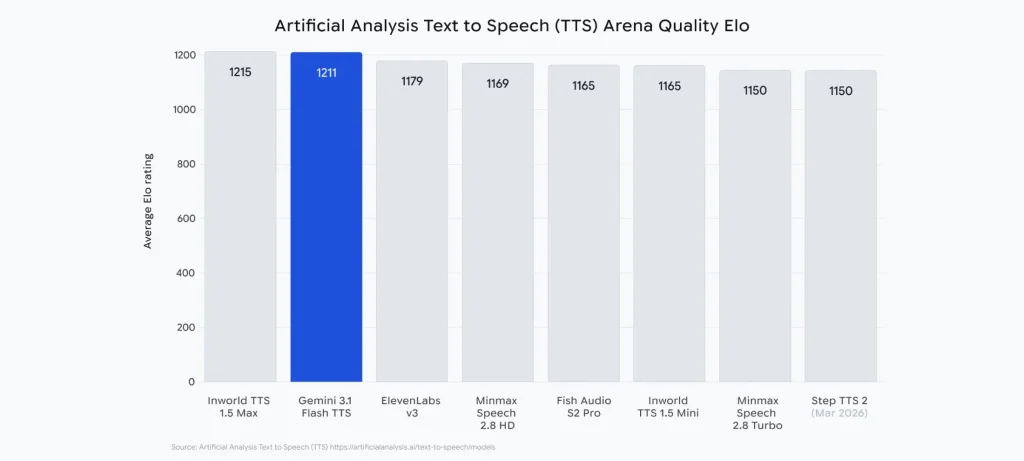
- تحقيق ترتيب متقدم (#2) في تصنيف Artificial Analysis لجودة الصوت
- دعم الحوارات متعددة المتحدثين بشكل طبيعي
- إمكانية تصدير الإعدادات ككود عبر Gemini API لضمان الاتساق
- متاح للمطورين عبر Google AI Studio وللشركات عبر Vertex AI
ويُعد إدخال “Audio Tags” من أبرز الابتكارات، حيث يمكن للمستخدم تحديد أسلوب الصوت داخل النص نفسه، مثل تغيير النبرة أو السرعة أو حتى اللهجة أثناء الجملة، مما يمنح تحكماً غير مسبوق في الأداء الصوتي.
الأهداف المستقبلية
تسعى Google من خلال هذا النموذج إلى تطوير جيل جديد من تطبيقات الصوت الذكي.
- تمكين المطورين من إنشاء تجارب صوتية أكثر واقعية وتفاعلية
- تحسين جودة المحتوى الصوتي في التطبيقات والمنصات الرقمية
- دعم إنشاء شخصيات صوتية مميزة ومتسقة عبر المشاريع
- توسيع استخدام الذكاء الاصطناعي في مجالات الإعلام والتعليم
- تعزيز الانتشار العالمي عبر دعم لغات متعددة
كما يمثل هذا التطور خطوة مهمة نحو جعل الذكاء الاصطناعي قادراً على إنتاج محتوى صوتي يعكس المشاعر والأسلوب البشري بشكل دقيق.
في النهاية، يؤكد Gemini 3.1 Flash أن مستقبل الصوت بالذكاء الاصطناعي لن يقتصر على القراءة الآلية، بل سيتحول إلى أداء صوتي متكامل يمكن توجيهه والتحكم فيه كما لو كان ممثلاً حقيقياً.





