الاختبار الأخير للبشرية يقيس حدود الذكاء الاصطناعي
أطلق اتحاد عالمي يضم نحو 1000 باحث ما يُعرف باسم “الاختبار الأخير للبشرية” (Humanity’s Last Exam)، وهو معيار تقييم جديد يضم 2500 سؤال صُمم خصيصاً لمعالجة مشكلة تفوق أنظمة الذكاء الاصطناعي على الاختبارات الأكاديمية التقليدية التي لم تعد تقيس قدراتها بدقة.
تفاصيل الخبر
يهدف الاختبار الأخير للبشرية “Humanity’s Last Exam” إلى إنشاء معيار طويل الأمد وشفاف لقياس قدرات أنظمة الذكاء الاصطناعي المتقدمة، خاصة بعد أن أصبحت النماذج الحديثة قادرة على تحقيق نتائج مرتفعة في اختبارات قياسية سابقة بسهولة.
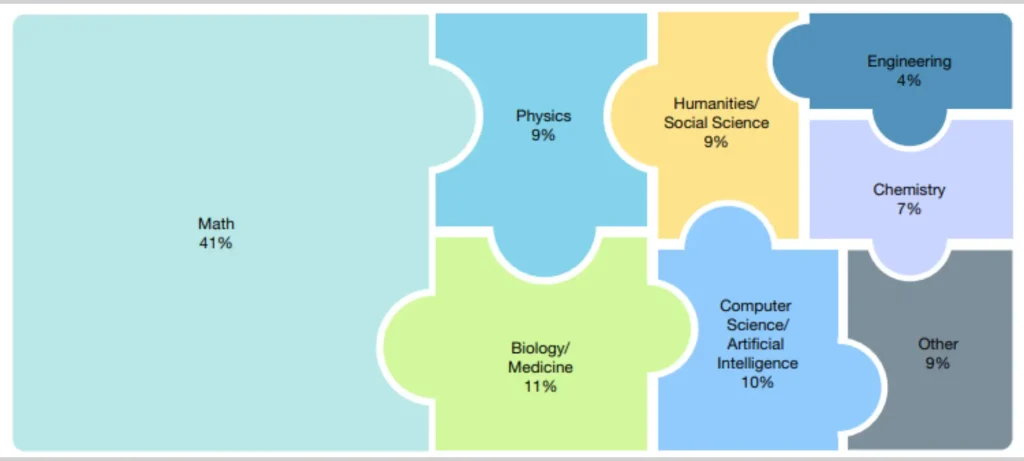
- يتكون من 2500 سؤال تغطي الرياضيات، العلوم الإنسانية، العلوم الطبيعية، اللغات القديمة، وتخصصات دقيقة للغاية.
- صاغ الأسئلة خبراء من مختلف أنحاء العالم مع التأكد من وجود إجابة واحدة واضحة وقابلة للتحقق لكل سؤال.
- صُممت الأسئلة بحيث لا يمكن حلها فوراً عبر البحث على الإنترنت.
- تم اختبار كل سؤال على نماذج ذكاء اصطناعي معروفة، وأُزيل أي سؤال استطاع أي نظام الإجابة عنه بشكل صحيح.
- تتضمن الأمثلة ترجمة نقوش تدمرية قديمة وتحديد تراكيب تشريحية مجهرية في الطيور.
وقد أظهرت النتائج الأولية أداءً متواضعاً للنماذج، إذ سجل GPT-4 نسبة 2.7%، بينما حقق Claude 3.5 Sonnet نسبة 4.1%. أما النماذج الأحدث مثل Gemini 3.1 Pro وClaude Opus 4.6 فقد وصلت إلى ما بين 40% و50% تقريباً، ما يعكس تقدماً ملحوظاً لكنه لا يزال بعيداً عن الإتقان الكامل.
الأهداف المستقبلية
يركز المشروع على وضع معيار قوي ومستدام لقياس التقدم الحقيقي في الذكاء الاصطناعي بعيداً عن الأسئلة السهلة أو القابلة للحفظ.
- توفير مقياس طويل الأمد يمكن الاعتماد عليه لمتابعة تطور النماذج المتقدمة.
- تسليط الضوء على الفجوات بين التفكير البشري العميق وقدرات الأنظمة الحالية.
- تحفيز تطوير نماذج أكثر قدرة على التحليل والاستدلال المعقد.
- دعم الشفافية في تقييم الأنظمة أمام المجتمع العلمي وصناع القرار.
- تشجيع التعاون الدولي بين الباحثين في تخصصات متعددة.
في الختام، يمثل “الاختبار الأخير للبشرية” محاولة جادة لإعادة ضبط معايير تقييم الذكاء الاصطناعي. كما يعكس إدراكاً متزايداً بأن قياس القدرات الحقيقية يتطلب تحديات تتجاوز حدود الاختبارات التقليدية.