

جوجل تضيف ميزة Agentic Vision إلى Gemini 3 Flash
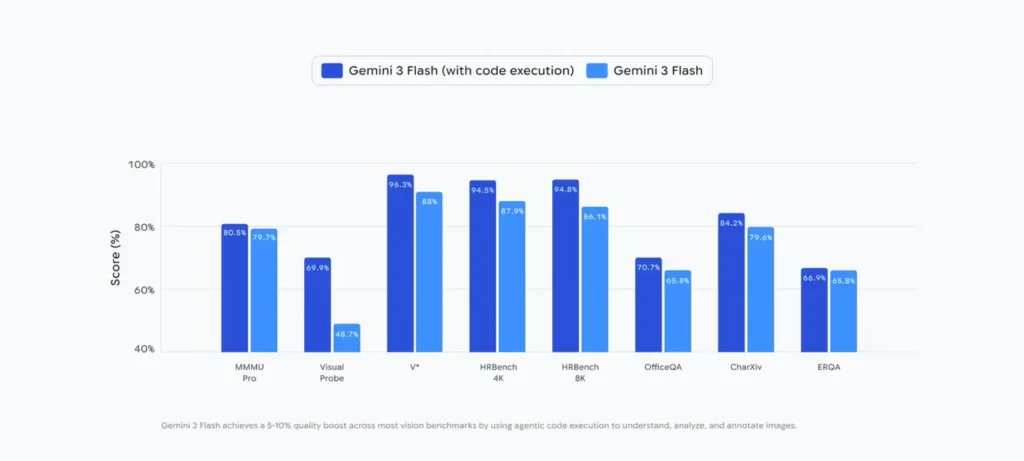
أطلقت جوجل ميزة جديدة في نموذج Gemini 3 Flash تُسمى Agentic Vision، تتيح للموديل التكبير، التعليق، وتحرير الصور لتقديم إجابات أكثر دقة، مع تحسين الجودة بنسبة 5-10% في المهام البصرية.
تفاصيل الخبر
تقوم هذه الميزة بتحويل فهم الصورة من مجرد عرض ثابت إلى عملية نشطة تعتمد على التفكير والتنفيذ والملاحظة.
- Think: يقوم النموذج بتحليل الصورة والسؤال المطروح، ويضع خطة متعددة الخطوات للتعامل مع التفاصيل الدقيقة.
- Act: ينفذ الموديل كود بايثون للتلاعب بالصور مثل القص، التدوير، أو التعليق، أو لإجراء حسابات بصرية مثل عدّ العناصر.
- Observe: تُضاف النسخ المعدلة من الصورة إلى سياق النموذج ليتمكن من التحقق من البيانات بصريًا قبل تقديم الإجابة النهائية.
تطبيقات Agentic Vision
- التكبير والفحص الدقيق: يكتشف Gemini 3 Flash التفاصيل الصغيرة تلقائيًا، مثل الأرقام التسلسلية أو علامات الشوارع، ويطبق عمليات فحص متكررة لضمان الدقة.
- تعليق الصور: يمكن للموديل رسم مربعات وعلامات رقمية على الصور لتأكيد حساباته، مثل عدّ أصابع اليد بدقة.
- الرياضيات البصرية والرسم البياني: يستطيع تحليل جداول معقدة وإنشاء مخططات عبر بايثون، ما يقلل من التخمين ويزيد من موثوقية النتائج.
الأهداف المستقبلية
تخطط جوجل لتوسيع قدرات Agentic Vision لتشمل:
- سلوكيات جديدة تعتمد على الكود بشكل ضمني مثل التدوير والتحليل البصري متعدد الخطوات دون الحاجة لتعليمات صريحة.
- دمج أدوات إضافية مثل البحث العكسي عن الصور والويب لتعميق فهم العالم بصريًا.
- توسيع الميزة لتشمل جميع أحجام نماذج Gemini وليس فقط Flash.
الميزة متاحة اليوم عبر Gemini API في Google AI Studio وVertex AI، كما بدأت بالظهور في تطبيق Gemini، مما يفتح المجال للمطورين لاستكشاف استخدامات جديدة للرؤية الحاسوبية الموجهة بالكود.
في النهاية، Agentic Vision تجعل Gemini 3 Flash أكثر ذكاءً في التعامل مع الصور، مع قدرة على الفهم البصري الدقيق واتخاذ إجراءات محسوبة، وهو تطور كبير في نماذج الذكاء الاصطناعي البصرية.





