

OCR-2 من DeepSeek مفتوح المصدر لقراءة المستندات بكفاءة عالية
أعلنت شركة DeepSeek عن إطلاق نموذج DeepSeek-OCR-2 مفتوح المصدر، وهو نموذج متقدم لقراءة واستخراج النصوص من المستندات، يحقق أداءً متفوقًا على معايير التقييم مع كفاءة أعلى في استخدام الرموز، ما يجعله خيارًا عمليًا لمعالجة الوثائق على نطاق واسع.
تفاصيل الخبر
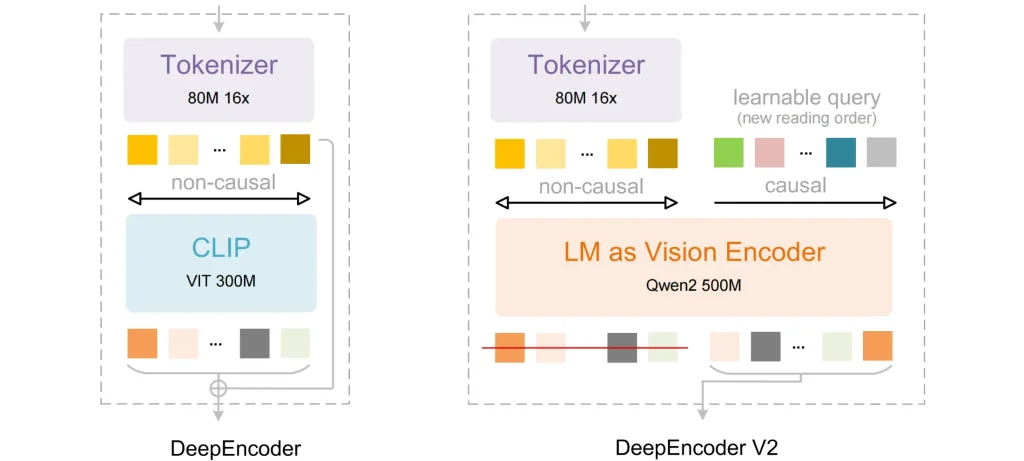
كشفت DeepSeek AI عن نموذج DeepSeek-OCR-2 كإصدار جديد من تقنيات التعرف الضوئي على الحروف، مصمم لفهم المستندات بطريقة أقرب إلى أسلوب القراءة البشرية، بدل الاعتماد على المسح التقليدي القائم على تقسيم الصورة إلى مربعات ثابتة. ويهدف النموذج إلى تحسين الدقة وتقليل التكلفة الحسابية في الوقت نفسه.
أبرز ما يميز DeepSeek-OCR-2:
- تفوقه على نماذج OCR الأخرى في اختبارات الأداء القياسية، خاصة في المستندات المعقدة.
- كفاءة أعلى في استخدام الرموز، ما يقلل من استهلاك الموارد ويخفض تكلفة المعالجة.
- قدرة محسنة على قراءة الجداول، الصيغ الرياضية، والنصوص متعددة الأعمدة بدقة أعلى.
- دعم عدد كبير من اللغات، ما يجعله مناسبًا للاستخدام العالمي.
- إمكانية إخراج النتائج بتنسيقات منظمة مثل النص المنسق أو البيانات القابلة للمعالجة برمجيًا.
- إتاحته كنموذج مفتوح المصدر بالكامل، ما يسمح للمطورين والباحثين باستخدامه وتعديله بحرية.
ويُعد هذا الإصدار خطوة مهمة في سياق تسارع تطوير النماذج المفتوحة المصدر، خاصة في مجال فهم المستندات الذي يُعد عنصرًا أساسيًا في الأتمتة، تحليل البيانات، وبناء أنظمة الذكاء الاصطناعي المتقدمة.
الأهداف المستقبلية
يعكس المسار المستقبلي لـ DeepSeek-OCR-2 طموح الشركة في إعادة تعريف كفاءة قراءة المستندات ودقتها، مع التركيز على التوسّع التقني وتعزيز الاعتماد المجتمعي للنموذج المفتوح المصدر.
وتشمل الأهداف:
- تحسين دقة النموذج في التعامل مع المستندات شديدة التعقيد.
- توسيع دعم اللغات والأنماط المختلفة من الوثائق.
- تعزيز تكامل النموذج مع أنظمة الذكاء الاصطناعي الأخرى وسير العمل المؤسسي.
- تشجيع مساهمات مجتمع المطورين لتطوير قدرات النموذج بشكل مستمر.
يمثل DeepSeek-OCR-2 نقلة نوعية في مجال قراءة المستندات بالذكاء الاصطناعي، حيث يجمع بين الأداء العالي والكفاءة التشغيلية والانفتاح على المجتمع، ما يجعله أداة واعدة للمطورين والمؤسسات في عصر البيانات المتسارع.





