ميتا تطور ذكاءً اصطناعياً يكتشف أخطاءه البرمجية ويصلحها ذاتياً
أعلن باحثو ميتا عن طريقة تدريب جديدة تُمكّن نماذج الذكاء الاصطناعي من تحسين قدراتها البرمجية عبر اكتشاف أخطائها وإصلاحها دون الاعتماد على بيانات بشرية.
تفاصيل البحث
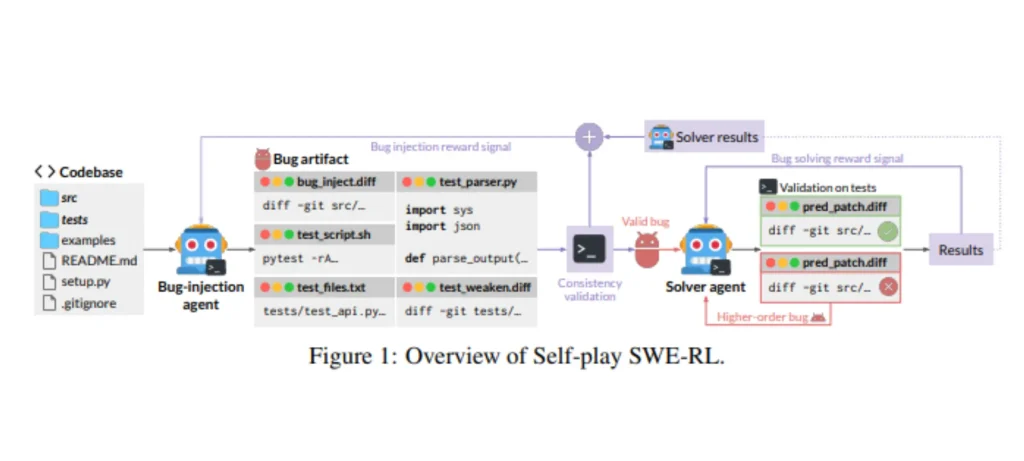
كشفت وحدة FAIR للأبحاث في شركة ميتا عن بحث جديد يعتمد على أسلوب مبتكر يُعرف باسم Self-play SWE-RL، وهو نهج تدريبي مستوحى من تقنيات التعلم الذاتي التي أحدثت نقلة نوعية في مجالات أخرى مثل الألعاب. تقوم الفكرة على استخدام نموذج ذكاء اصطناعي واحد يؤدي دورين متكاملين في الوقت نفسه.
في هذا النظام، يعمل النموذج أولاً كـ “مُدخل أخطاء” يقوم عمداً بإفساد الشيفرة البرمجية، ثم يتحول إلى “مُصلح” يحاول اكتشاف هذه الأخطاء وتصحيحها. ومع تكرار هذه العملية، يتعلم النموذجان – رغم كونهما نموذجاً واحداً – من بعضهما البعض دون أي تدخل بشري مباشر.
وقد تم اختبار هذا النهج على معيار SWE-bench Verified المخصص لتقييم قدرات نماذج البرمجة، حيث حقق تحسناً ملحوظاً مقارنة بنقطة البداية، وتجاوز حتى نماذج تم تدريبها على بيانات بشرية.
أبرز نتائج البحث:
- استخدام نموذج واحد بدورين: إدخال الأخطاء ثم إصلاحها.
- تحسن الأداء بأكثر من 10 نقاط على SWE-bench Verified.
- التفوق على نماذج تعتمد على بيانات بشرية من GitHub.
- توليد ما يُعرف بـ “الأخطاء عالية المستوى” من محاولات الإصلاح الفاشلة.
- إنشاء منهج تعلم متطور يتكيف تلقائياً مع مستوى مهارة النموذج.
ويُعد هذا التدرج الذاتي في الصعوبة عاملاً أساسياً في قدرة النموذج على الاستمرار في التحسن دون سقف واضح.
الأهداف المستقبلية
يشير هذا البحث إلى مسار جديد في تطوير وكلاء البرمجة بالذكاء الاصطناعي، حيث تسعى ميتا إلى:
- تقليل الاعتماد على بيانات بشرية محدودة وقابلة للنضوب.
- تمكين النماذج من توليد بيانات تدريب غير محدودة من الشيفرات البرمجية.
- رفع كفاءة وكلاء البرمجة في البيئات الواقعية والمعقدة.
- تطبيق مبدأ التعلم الذاتي، المشابه لنهج AlphaZero، في هندسة البرمجيات.
يمثل هذا البحث خطوة مهمة نحو ذكاء اصطناعي أكثر استقلالية، قادر على التعلم والتحسن الذاتي في البرمجة، ما قد يغير مستقبل تطوير البرمجيات جذرياً.