

مايكروسوفت تصدر VibeVoice لأصوات واقعية متعددة المتحدثين
قدّمت مايكروسوفت نموذج VibeVoice المفتوح الذي يتيح توليد كلام واقعي طويل بدقة عالية، مع قدرة على محاكاة أربعة أصوات مختلفة، مما يجعله مناسبًا للبودكاست والمحتوى السمعي المطوّل.
تفاصيل الخبر
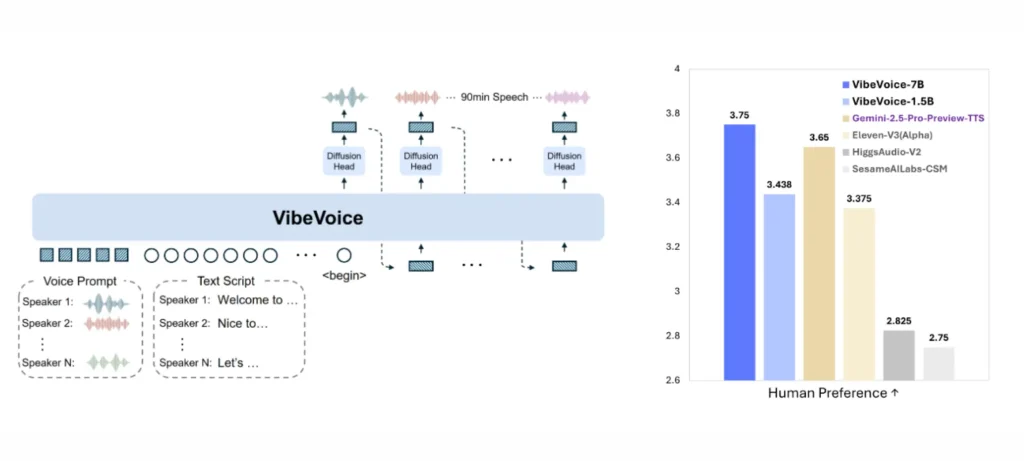
يقدم نموذج VibeVoice نهجًا جديدًا لإنتاج صوت اصطناعي واقعي في محادثات طويلة ومتعددة المتحدثين.
- يعتمد على مُرمّزات صوتية ودلالية تعمل بإطار منخفض جدًا يصل إلى 7.5 إطار في الثانية للحفاظ على الجودة وتقليل العبء الحسابي.
- يستخدم نموذجًا لغويًا كبيرًا لفهم بنية النص وتدفق الحوار قبل توليد الصوت.
- يعتمد رأس الانتشار لإنتاج تفاصيل صوتية عالية الدقة وواقعية.
- قادر على توليد صوت يصل إلى 90 دقيقة مع دعم أربعة متحدثين مستقلين في النص الواحد.
- يهدف إلى تحسين جودة البودكاستات والمحتوى السمعي المطوّل بسهولة أكبر من الأدوات السابقة.
- تم إيقاف المستودع مؤقتًا بعد اكتشاف استخدامات غير متوافقة مع الهدف البحثي المعلن.
الأهداف المستقبلية
تسعى مايكروسوفت من خلال نموذج VibeVoice إلى دعم تطوير الصوت الاصطناعي على نطاق واسع.
- تعزيز أنظمة TTS لتصبح أكثر طبيعية وتعبيرًا في المحادثات الطويلة.
- دعم المطورين في إنشاء محتوى صوتي متنوع مثل الروايات والبودكاست والمحادثات التفاعلية.
- فتح المجال أمام الباحثين للمساهمة في تطوير النموذج ضمن إطار الاستخدام المسؤول.
- رفع مستوى كفاءة الأنظمة الصوتية من خلال تحسين إدارة الحوار طويل المدى بتعدد المتحدثين.
يمثل VibeVoice خطوة مهمة نحو تطوير الصوت الاصطناعي طويل المدى والمتعدد الأصوات، مما يمهد لثورة جديدة في المحتوى السمعي الإبداعي. ويعتمد مستقبل هذا التقدم على الاستخدام المسؤول والتطوير المستمر.





