

Baidu تكشف عن ERNIE-4.5-VL-28B-A3B-Thinking
أعلنت شركة Baidu عن نموذجها الأحدث ERNIE-4.5-VL-28B-A3B-Thinking، وهو نموذج متعدد الوسائط يجمع بين النص والصورة والفيديو، ويستهدف تحسين قدرات التفكير البصري-اللغوي والتحليل العميق للمحتوى.
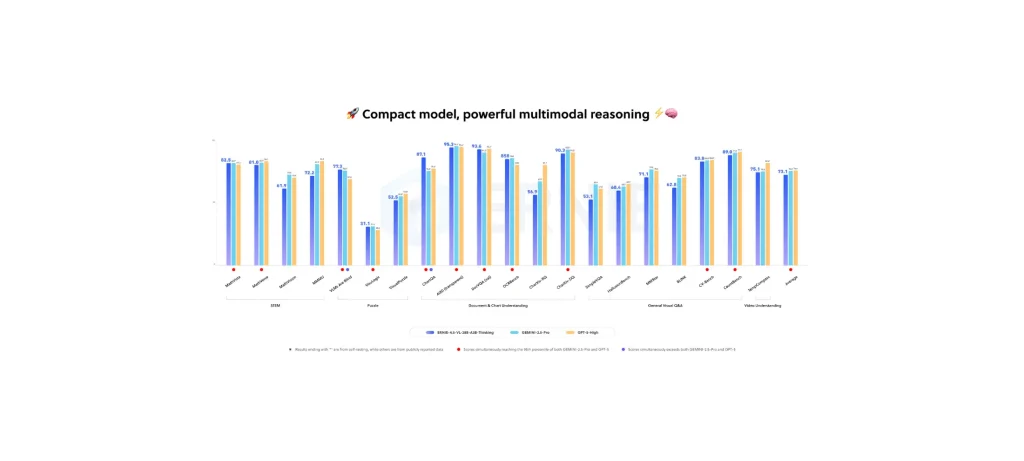
أبرز مميزات النموذج
يأتي النموذج الجديد بتقنيات حديثة تجعل منه منافسًا جديًا لأقوى نماذج الذكاء الاصطناعي الحالية:
- بنية Mixture of Experts (MoE): يضم نحو 30 مليار معاملة، مع تفعيل 3 مليارات فقط لكل استدلال بفضل مفتاح A3B، ما يزيد من الكفاءة ويقلل التكلفة.
- تدريب بصري-لغوي متقدّم: تم تدريبه على نطاق واسع من البيانات التي تربط بين النصوص والصور لرفع مستوى الفهم الدلالي.
- تقنيات GSPO وIcePop: لتعزيز التعلم المعزّز وتحسين التفكير مع الصور، بما يشمل التكبير (zoom-in) والبحث البصري.
- قدرات تحليلية متنوعة: من تحليل الرسوم البيانية والمخططات إلى تتبع التغيّرات الزمنية في الفيديو.
- استخدام الأدوات: يمكن للنموذج تنفيذ عمليات مثل بحث الصور عند الحاجة إلى معرفة متخصصة أو تفاصيل دقيقة.
الأداء والموقع التنافسي
بعد استعراض مميزات النموذج التقنية، برز أداء ERNIE-4.5-VL-28B-A3B-Thinking كأحد أبرز نقاط قوته مقارنة بالمنافسين:
- أعلنت Baidu أن النموذج يتفوّق على GPT-5 (High) وGemini 2.5 Pro في عدد من اختبارات الرؤية والفهم البصري.
- يتميّز بقدرته على تحقيق نتائج عالية باستخدام معاملاته النشطة فقط، مما يقلل التكلفة التشغيلية دون التأثير على الأداء.
- يهدف إلى الجمع بين الفهم العميق للوسائط وقدرة التفكير التحليلي، ما يجعله خطوة نحو وكلاء متعددين الوسائط أكثر ذكاءً واستقلالية.
الأهداف المستقبلية
مع هذا الإصدار، تسعى Baidu إلى:
- تطوير نماذج قادرة على التفكير البصري-اللغوي المتكامل لتطبيقات التعليم والتحليل الصناعي والتقني.
- تعزيز الكفاءة في تشغيل النماذج الضخمة دون التضحية بالجودة.
- دعم تطوير وكلاء ذكيين متعددين الوسائط قادرين على فهم وتفسير العالم الواقعي بمستوى يشبه الإنسان.
- المساهمة في سباق عالمي لتقنيات التحليل متعدد الوسائط التي تمزج بين اللغة والرؤية والفيديو.
يمثل نموذج ERNIE-4.5-VL-28B-A3B-Thinking خطوة جديدة في سباق الذكاء الاصطناعي متعدد الوسائط، مؤكدًا أن المنافسة المقبلة لن تُقاس بعدد المعاملات فقط، بل بمدى عمق الفهم والتحليل بين النص والصورة والفيديو.





