

علي بابا تطلق إصدارات مدمجة من Qwen3-VL تتفوق على GPT-5 Nano
فريق Qwen التابع لشركة علي بابا كشف عن نسخ مدمجة وأكثر كفاءة من نموذج Qwen3-VL بإصداريه 4B و8B، تتفوق في الأداء على نماذج مثل Gemini 2.5 Flash Lite وGPT-5 Nano.
تفاصيل الخبر
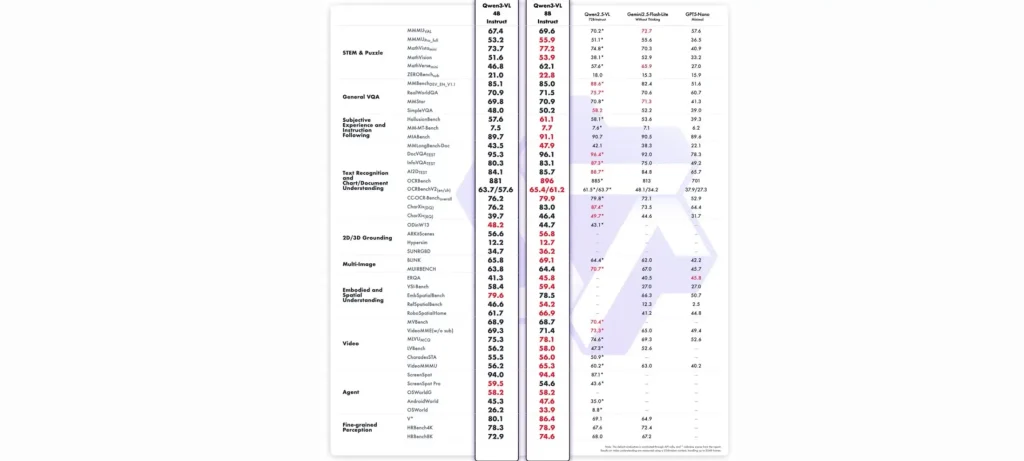
أعلنت Alibaba Cloud عن إطلاق نسخ جديدة من نموذجها متعدد الوسائط Qwen3-VL، صُممت لتوفير أداء قوي مع تقليل استهلاك الموارد. الإصدارات الجديدة تأتي بحجمين — 4B و8B — وتتوفر بنسختين: Instruct للتفاعل وThinking للاستدلال المتقدم.
- الإصدارات الجديدة تتميز بانخفاض استهلاك VRAM مع الحفاظ على جميع قدرات Qwen3-VL الأصلية.
- الأداء العام تفوق على نماذج مثل Gemini 2.5 Flash Lite وGPT-5 Nano في معظم الاختبارات.
- أظهرت النتائج تفوقًا في مجالات العلوم والهندسة (STEM)، وفهم الفيديو، وتحليل الصور والنصوص (VQA وOCR)، وأداء المهام التفاعلية للـAgents.
- في بعض المقاييس، حققت النماذج نتائج مقاربة للنموذج الضخم Qwen2.5-VL-72B الذي أطلق قبل ستة أشهر فقط.
- كما أعلنت علي بابا عن إصدارات FP8 لتحسين الكفاءة عند النشر في بيئات محدودة الموارد.
روابط النماذج متاحة عبر:
الأهداف المستقبلية
تواصل Alibaba Cloud الاستثمار في تحسين كفاءة النماذج متعددة الوسائط لمنافسة الشركات العالمية الرائدة.
- تقديم حلول ذكاء اصطناعي قابلة للنشر على نطاق أوسع وأقل تكلفة.
- تعزيز القدرات المنطقية والتحليلية عبر الإصدار “Thinking”.
- دعم المبدعين والمطورين بإصدارات مفتوحة المصدر سهلة الاستخدام.
- تقليص الفجوة بين النماذج المدمجة والنماذج العملاقة في الأداء الفعلي.
بفضل إطلاق Qwen3-VL-4B و8B، تثبت علي بابا أن الكفاءة لا تعني التنازل عن القوة. خطوة جديدة تضع الصين في صدارة سباق الذكاء الاصطناعي متعدد الوسائط عالميًا.





