

إطلاق TOUCAN أكبر مجموعة بيانات لتدريب وكلاء الذكاء الاصطناعي
أعلن باحثون من MIT وIBM وجامعة واشنطن عن إطلاق TOUCAN، أكبر مجموعة بيانات مفتوحة لتدريب وكلاء الذكاء الاصطناعي على استخدام الأدوات الحقيقية، بما يشمل 1.5 مليون تفاعل عبر 495 خادم MCP.
تفاصيل الخبر
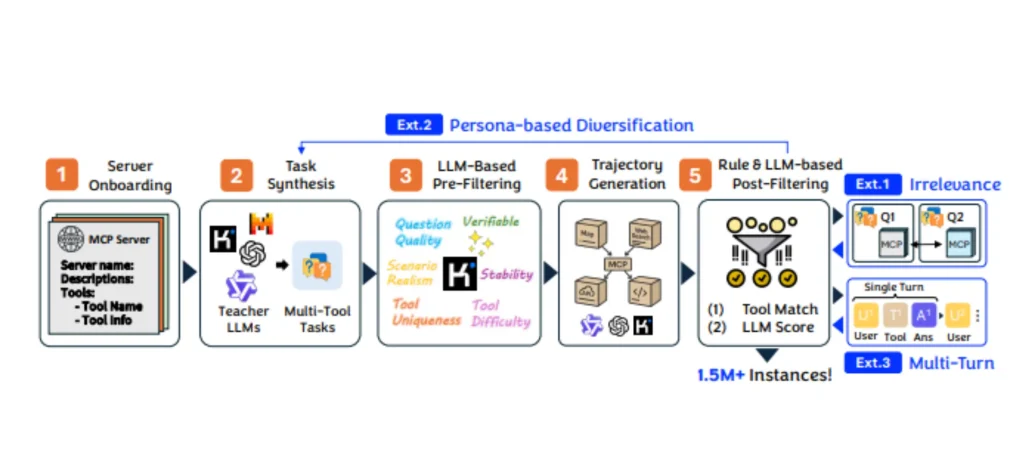
تمثل TOUCAN نقلة نوعية في تدريب الوكلاء على التعامل مع البيئات الواقعية، بخلاف المجموعات السابقة التي اعتمدت على المحاكاة. تحتوي المجموعة على أكثر من 2,000 أداة تم جمع بياناتها من 495 خادم MCP حقيقي.
خطوات إنشاء توكّان:
- توليد المهام: خمسة نماذج لغوية أنتجت مجموعة متنوعة من مهام استخدام الأدوات.
- فلترة الجودة: تم فحص المهام لضمان الواقعية والدقة.
- تفاعل الوكلاء: ثلاثة نماذج “معلمة” نفذت المهام، مولدة مسارات تفاعلية.
- آليات التوسع: تشمل التباينات، المحادثات متعددة الأدوار، والقيود لزيادة التنوع.
- التحقق: استخدام تقنيات قائمة على القواعد والنماذج للتحقق من جودة البيانات.
أظهرت النماذج المدربة على TOUCAN تحسنًا ملحوظًا في الأداء، مثل:
- Qwen2.5-7B-Instruct: +3.16%
- Qwen2.5-14B-Instruct: +7.40%
- Qwen2.5-32B-Instruct: +8.72% على معيار BFCL V3
الأهداف المستقبلية
تهدف TOUCAN إلى دفع حدود تطوير الوكلاء مفتوحة المصدر وجعلهم قادرين على أداء المهام الواقعية المعقدة بكفاءة أعلى:
- تمكين الوكلاء من التعامل مع أدوات حقيقية وليس بيئات محاكاة فقط.
- تحسين أداء النماذج الكبيرة والصغيرة في المهام متعددة الخطوات.
- زيادة تنوع المهام والتفاعلات لتدريب وكلاء أكثر مرونة وواقعية.
- دعم التطوير المفتوح المصدر للوكلاء ليصبحوا متاحين لمجتمع البحث العالمي.
- تسريع تطبيقات الذكاء الاصطناعي العملية في البيئات الواقعية والصناعات المختلفة.
مع إطلاق توكّان، تتجه أبحاث الذكاء الاصطناعي نحو تمكين الوكلاء من التعامل مع العالم الواقعي بكفاءة أكبر، مما يعزز فرص تطوير أنظمة ذكية أكثر قوة ومرونة.





