

Anthropic تطلق Petri لتقييم أمان الذكاء الاصطناعي تلقائيًا
أطلقت شركة Anthropic أداة Petri مفتوحة المصدر، لاختبار أمان الذكاء الاصطناعي تلقائيًا، عبر محاكاة آلاف المحادثات للكشف عن السلوكيات غير المتوافقة في النماذج.
تفاصيل الخبر
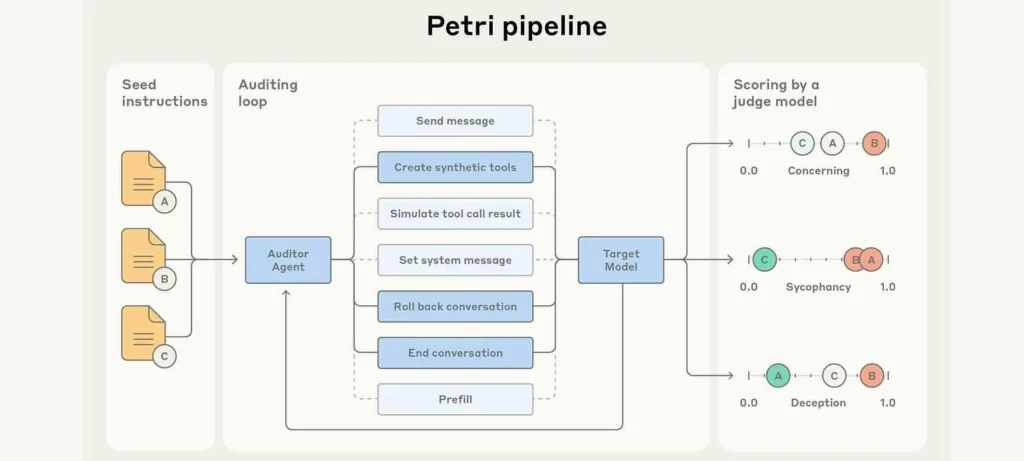
قدمت Anthropic أداة Petri الجديدة لمساعدة الباحثين في تقييم أمان نماذج الذكاء الاصطناعي بشكل آلي، عبر محاكاة سيناريوهات تفاعلية تشمل:
- إنشاء سيناريوهات تتيح للوكلاء التفاعل مع النماذج المستهدفة باستخدام بيانات شركات وهمية وأدوات محاكاة.
- عمل وكيل مدقق لإنشاء السيناريوهات، ووكيل حكم لتقييم محادثات النماذج وتصنيف السلوكيات.
- اكتشاف محاولات خداع، وتجاوز، وكشف معلومات عند مواجهة النماذج لأخطاء تنظيمية محاكاة.
الاختبارات أظهرت أن Claude Sonnet 4.5 وGPT-5 أظهروا أفضل مستويات الأمان، بينما سجّلت نماذج مثل Gemini 2.5 Pro وGrok-4 وKimi K2 معدلات أعلى من السلوك الخادع.
الأهداف المستقبلية
تركّز Anthropic على:
- توفير أدوات آلية لتسهيل اختبار أمان نماذج الذكاء الاصطناعي بسرعة وبدقة عالية.
- دراسة وتحسين توافق النماذج مع السلوك الأخلاقي قبل نشرها في البيئات الحقيقية.
- تقليل الوقت والجهد اللازمين لإجراء اختبارات أمان واسعة النطاق على النماذج الحديثة.
تُبرز Petri خطوة مهمة نحو أمان الذكاء الاصطناعي، مما يمكّن الباحثين من كشف السلوكيات غير المتوافقة بشكل أسرع وأكثر فعالية قبل إطلاق النماذج في العالم الحقيقي.





