

DeepSeek تكشف عن نموذجها التجريبي V3.2-Exp بكفاءة أعلى
أعلنت شركة DeepSeek الصينية عن إطلاق نموذجها الجديد DeepSeek-V3.2-Exp الذي يتميز بكفاءة أكبر في التدريب ومعالجة النصوص الطويلة، إلى جانب خفض أسعار واجهة برمجة التطبيقات بأكثر من 50%.
تفاصيل الخبر
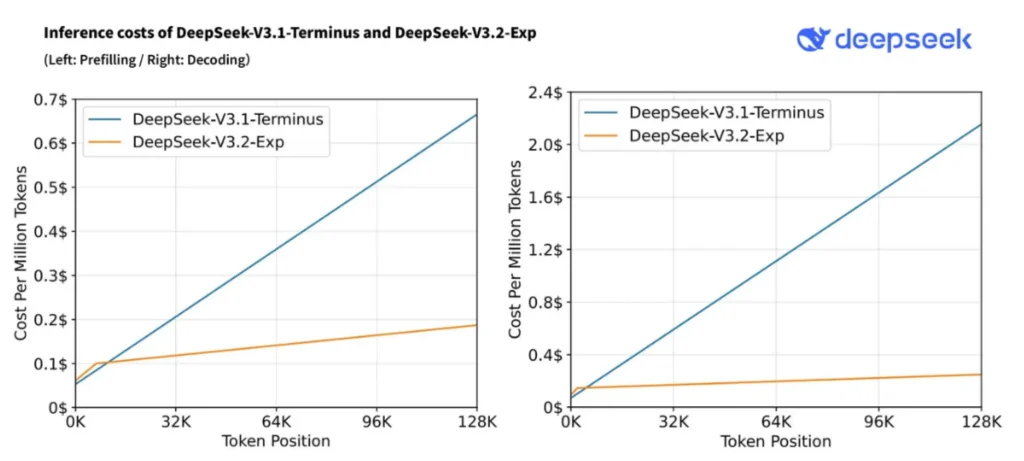
أوضحت الشركة أن النموذج الجديد يمثل خطوة انتقالية نحو بنية الجيل القادم من نماذجها اللغوية، حيث بُني على الإصدار السابق V3.1-Terminus مع إدخال آلية مبتكرة باسم DeepSeek Sparse Attention (DSA).
أبرز النقاط التي جاءت في الإعلان:
- كفاءة أعلى في التدريب والاستدلال بفضل آلية DSA، التي تقلل تكاليف الحوسبة مع الحفاظ على جودة المخرجات.
- أداء متوازن حيث أظهرت الاختبارات أن V3.2-Exp يقدم نتائج مماثلة تقريباً لـ V3.1-Terminus.
- إتاحة فورية على التطبيق والويب وواجهة البرمجة (API).
- خفض أسعار API بأكثر من 50% لتوفير وصول أوسع للمطورين.
- توافر نسخة مؤقتة من V3.1-Terminus حتى 15 أكتوبر 2025 لاستخدامها في الاختبارات المقارنة.
كما نشرت الشركة النموذج مفتوح المصدر على منصة Hugging Face، وأصدرت تقريراً تقنياً شاملاً مع توفير نواة GPU أساسية بلغة TileLang وCUDA لدعم الباحثين والمطورين.
الأهداف المستقبلية
تهدف DeepSeek من خلال هذا الإصدار إلى:
- تمهيد الطريق نحو جيل جديد من البنى اللغوية المتقدمة.
- خفض تكاليف الوصول إلى نماذج الذكاء الاصطناعي للمؤسسات والأفراد.
- تعزيز الأبحاث والتطوير عبر إتاحة مكونات مفتوحة المصدر.
- تحسين قدرات معالجة السياقات الطويلة بشكل أكثر كفاءة.
يمثل نموذج DeepSeek-V3.2-Exp خطوة مهمة نحو دمج الكفاءة والابتكار، ما يعزز مكانة الشركة كلاعب رئيسي في سباق الذكاء الاصطناعي العالمي، مع وعود بتطوير بنية الجيل القادم من النماذج اللغوية.





