آبل تكشف عن نموذج مانزانو لمعالجة الصور بفهمها وتوليدها
تعمل آبل على تطوير نموذج جديد باسم مانزانو (Manzano)، يدمج بين فهم الصور وتوليدها، في خطوة تسعى من خلالها لمنافسة أنظمة تجارية مثل GPT-4 من OpenAI ونماذج جوجل.
تفاصيل الخبر
أبرز المعلومات التي كشفت عنها آبل حول نموذج مانزانو:
- أكدت آبل أن النموذج لم يُطرح بعد للجمهور ولا يوجد له عرض تجريبي حتى الآن.
- اكتفى الباحثون بنشر ورقة بحثية على arXiv تضمنت عينات صور منخفضة الدقة لأوامر صعبة.
- تمت مقارنة نتائج مانزانو مع نماذج مفتوحة المصدر مثل DeepSeek Janus Pro، إضافة إلى أنظمة تجارية مثل GPT-4.
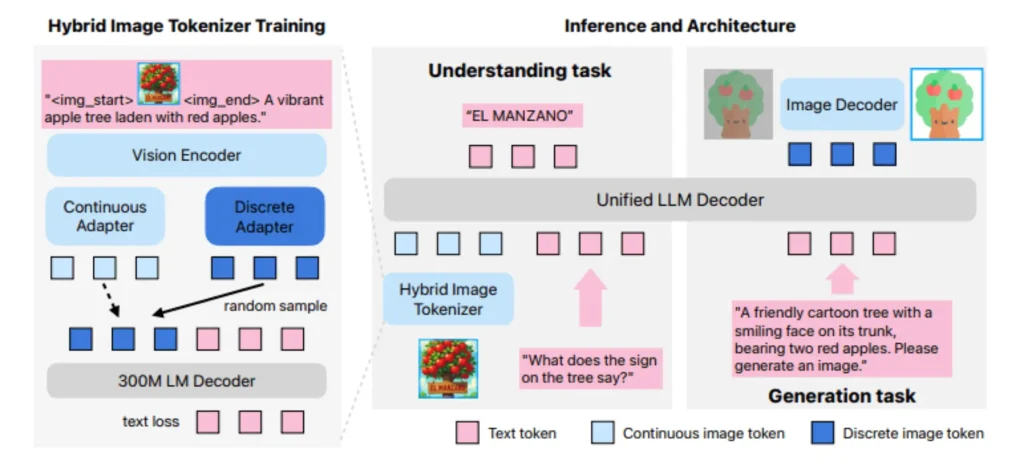
- الفكرة الأساسية للنموذج تقوم على هجين من تقنيات التشفير البصري: حيث يستعمل “Vision Tokenizer” مزدوج لإنتاج تمثيلات نصية وصورية ضمن فضاء دلالي واحد.
- يعتمد على LLM واحد موحد قادر على التنبؤ برموز النص والصورة معاً، مع مُفكك نشر (Diffusion Decoder) لتحويل الرموز البصرية إلى بكسلات.
- بحسب آبل، يحقق مانزانو نتائج متقدمة بين النماذج الموحدة، ومنافسة للنماذج المتخصصة، خصوصاً في المهام النصّية المعقدة.
الأهداف المستقبلية
تسعى آبل من خلال هذا النموذج إلى تحقيق مجموعة من الأهداف الرئيسية:
- اختبار قدرات مانزانو على التعلم المشترك لفهم وتوليد الصور دون تضارب في الأداء.
- تحسين قدرات النماذج الموحدة لمنافسة الأنظمة التجارية المغلقة.
- تطوير نسخ أكثر كفاءة من حيث جودة الصور ودقة الاستجابة للأوامر.
- تمهيد الطريق لدمج مثل هذه النماذج في تطبيقات آبل المستقبلية (مثل سيري أو أدوات التصميم والإنتاجية).
خاتمة
نموذج مانزانو يمثل خطوة جريئة من آبل نحو الذكاء الاصطناعي متعدد الوسائط، حيث يجمع بين الفهم والتوليد البصري. ورغم أنه ما زال في مرحلة بحثية، إلا أنه يفتح الباب أمام تطبيقات مستقبلية ثرية في عالم الصور واللغة.