

Scale AI يقدم SWE-Bench Pro معيار يرفع تحديات البرمجة الذكية
شركة Scale AI تقدم SWE-Bench Pro كإصدار مطور وأكثر صعوبة لتقييم أداء وكالات الذكاء الاصطناعي في تطوير البرمجيات، ما يجعله أقرب لبيئة العمل الحقيقية.
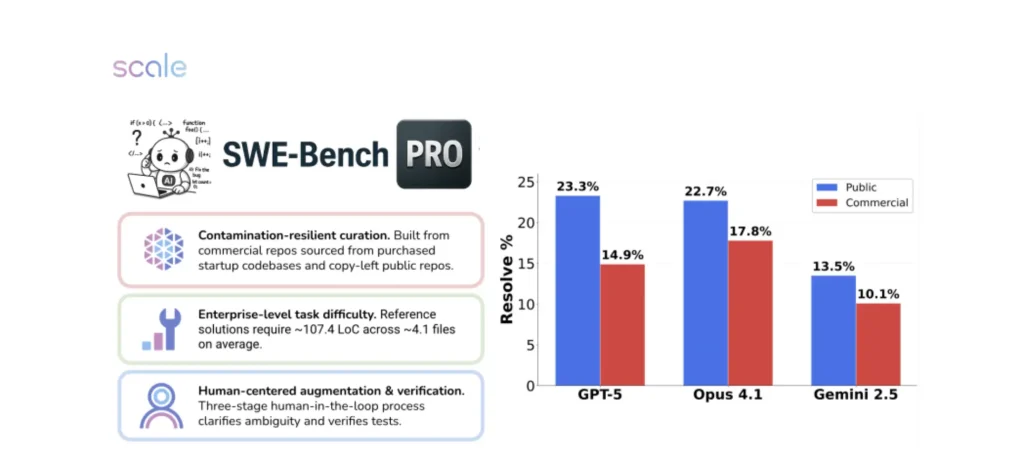
أهم التفاصيل والمزايا
قدمت Scale AI هذا المعيار الجديد ليختبر قدرات النماذج البرمجية في ظروف معقدة وواقعية، بعيدًا عن التحديات البسيطة السابقة.
- يحتوي على 1865 مهمة برمجية من 41 مستودع نشط.
- يغطي تطبيقات أعمال، خدمات بين الشركات، وأدوات مطورين.
- المهام تنقسم إلى: عامة (مفتوحة الوصول)، مخفية (غير متاحة للجميع)، وتجارية (من مستودعات خاصة).
- غالبية المهام طويلة المدى، قد تستغرق ساعات أو أيام لحلها من قبل مهندس محترف.
- تتضمن تعديلات متعددة الملفات (multi-file patches) وتغييرات برمجية واسعة.
- جميع المهام تم التحقق منها بشريًا وتوفير سياق كافٍ لحلها.
الأداء الحالي والتحديات
تظهر النتائج حتى الآن أن الطريق ما يزال طويلاً أمام النماذج البرمجية.
- معظم النماذج أقل من 25٪ في مقياس Pass@1.
- أفضل أداء حققه نموذج GPT-5 بنسبة 23.3٪ فقط.
- التحديات الرئيسية تشمل: بيئات معقدة، تعدد الملفات، وضخامة التعديلات المطلوبة.
لماذا هذا مهم؟
يساهم SWE-Bench Pro في رفع مستوى الاختبار العملي لوكالات الذكاء الاصطناعي، ويمكن تلخيص أهميته فيما يلي:
- تقريب اختبارات الذكاء الاصطناعي من الواقع الصناعي بدلاً من المهام البسيطة.
- تقليل مشكلة تلوث البيانات عبر مستودعات مخفية وخاصة.
- دفع الأبحاث نحو بناء نماذج قادرة على إنجاز تغييرات برمجية واسعة ومعقدة.
- توفير معيار قياس أقرب لمتطلبات فرق تطوير البرمجيات الحقيقية.
يمثل SWE-Bench Pro خطوة مهمة في اختبار قدرات الذكاء الاصطناعي في البرمجة، حيث يكشف الفجوة بين الأداء في المختبر وبين تحديات الواقع، ويفتح الطريق أمام تطوير نماذج أكثر كفاءة.





