

Alibaba تطلق Qwen-3-Max بتريليون معلمة وتتفوق على منافسيها
أعلنت Alibaba عن Qwen-3-Max-Preview، نموذج ضخم يضم أكثر من تريليون معلمة، ويتفوق على Qwen-3 السابق وClaude Opus 4 وKimi K2 وDeepSeek V3.1 في الاختبارات القياسية.
تفاصيل الخبر
فيما يلي أبرز النقاط حول إطلاق نموذج Qwen-3-Max-Preview من Alibaba:
- أطلقت علي بابا فريق Qwen أحدث نموذج لها باسم Qwen-3-Max-Preview، والذي يضم أكثر من 1 تريليون معلمة، مما يجعله أكبر نموذج لغوي ضخم في السلسلة حتى الآن.
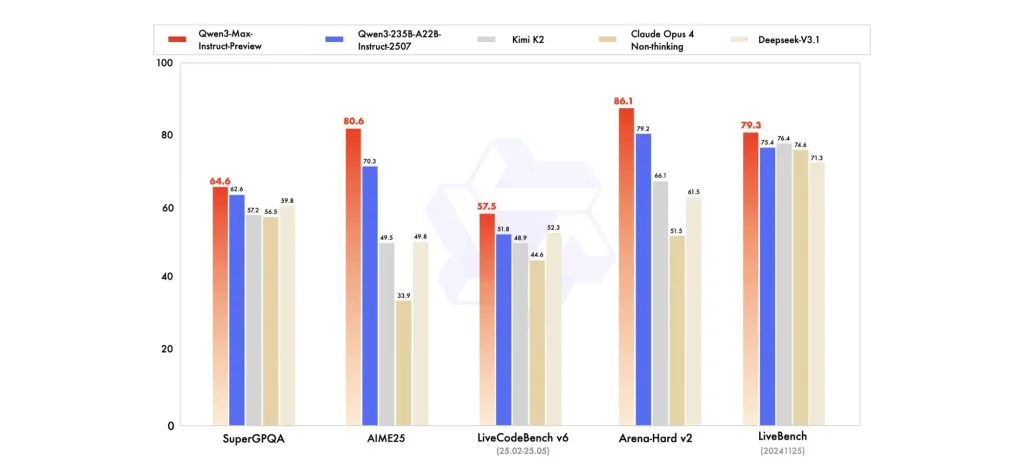
- في اختبارات الأداء، تفوق Qwen-3-Max-Preview على الإصدارات السابقة من Qwen مثل Qwen3-235B-A22B-2507، وتفوّق على نماذج مثل Claude Opus 4 (نسخة بلا تفكير)، Kimi K2، وDeepSeek V3.1 عبر عدة مؤشرات.
- دعم النموذج لنظام الذاكرة السياقية المركّبة يصل إلى 262,144 رمزًا، مع إمكانية تخزين السياق لتحسين الأداء في المحادثات الطويلة.
- لم يُصدر Qwen-3-Max-Preview تحت ترخيص مفتوح المصدر، بل هو متاح فقط من خلال API على Alibaba Cloud، Qwen Chat، OpenRouter، وأداة AnyCoder.
الأهداف المستقبلية
يسعى هذا الإطلاق إلى ترسيخ مكانة Alibaba في مجال النماذج اللغوية الضخمة من خلال:
- تعزيز الأداء من خلال نموذج ضخم يحقق تفوقًا في الاختبارات.
- دعم تطبيقات معقدة مثل البرمجة، الفهم متعدد اللغات، والمهام الطويلة.
- خفض الاعتماد على نماذج مفتوحة المصدر بتقديم نموذج متاح فقط عبر خدمات مدفوعة.
- تعزيز البنية التحتية AI ضمن Alibaba Cloud لدفع استراتيجيتها في الذكاء الاصطناعي.
يمثل Qwen-3-Max-Preview قفزة نوعية في عالم الذكاء الاصطناعي اللغوي، مزيلاً الحدود بين التفوّق التقني والتوجه التجاري المحكوم؛ حيث يُظهر أن علي بابا تصعد خطوات ثابتة نحو أن تصبح لاعبًا عالميًا رائدًا في هذا المجال.





