

LFM2-VL: نقلة نوعية في كفاءة النماذج متعددة الوسائط
تقدم Liquid AI نموذجها الجديد LFM2-VL لدمج النصوص والصور بكفاءة عالية، مما يفتح آفاقاً جديدة للتطبيقات على مختلف الأجهزة من الهواتف حتى الأنظمة المدمجة.
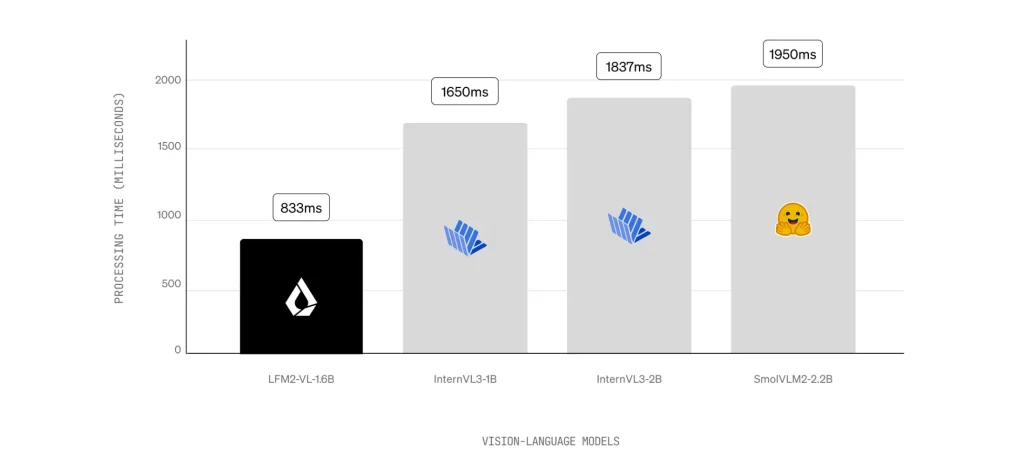
تفاصيل إطلاق LFM2-VL
في إعلان حديث، كشفت Liquid AI عن أول سلسلة من النماذج متعددة الوسائط التي تجمع بين معالجة النصوص والصور مع سرعة وكفاءة محسّنة:
- إصداران: LFM2-VL-450M للأجهزة محدودة الموارد، و LFM2-VL-1.6B للأداء الأقوى.
- أداء أسرع بمرتين على وحدات GPU مقارنة بالنماذج المنافسة.
- يدعم الصور بدقة حتى 512×512 بكسل مع تقسيم ذكي للصور الكبيرة دون فقدان تفاصيل.
- مرونة في ضبط التوازن بين السرعة والجودة أثناء الاستدلال.
- يعتمد على معمارية تتضمن مشفر بصري (SigLIP2)، موصل متعدد الوسائط، و نموذج لغوي أساسي من LFM2.
- مدرَّب على أكثر من 100 مليار رمز متعدد الوسائط لضمان تنوع البيانات وجودة الفهم.
- متاح الآن على Hugging Face بترخيص مفتوح مناسب للبحث والاستخدام التجاري للشركات الناشئة.
الأهداف المستقبلية
تركز Liquid AI في خططها القادمة على:
- تعزيز كفاءة التشغيل على الأجهزة الطرفية الصغيرة مثل الساعات الذكية.
- تطوير أدوات تكامل مع أطر العمل الشهيرة لتسهيل النشر والتخصيص.
- تحسين السرعة مقابل الجودة لتلبية احتياجات حالات الاستخدام المختلفة.
- تمكين الشركات الصغيرة والباحثين من الاستفادة تجارياً من النماذج دون قيود مرهقة.
- مواصلة البحث في المعمارية متعددة الوسائط لتحقيق أداء أفضل في مهام الفهم البصري والنصي.
يمثل LFM2-VL خطوة متقدمة نحو جعل النماذج متعددة الوسائط أكثر سرعة وكفاءة ومرونة، فاتحاً الباب أمام ابتكارات واسعة في الذكاء الاصطناعي المدمج.





