

OpenAI تكشف BrowseComp لتقييم قدرات الذكاء الاصطناعي بالتصفح
أطلقت OpenAI معيار BrowseComp الجديد لتقييم قدرة نماذج الذكاء الاصطناعي على تصفح الإنترنت بذكاء واسترجاع معلومات دقيقة ومتعددة المصادر.
معيار BrowseComp: مرحلة جديدة في تقييم ذكاء التصفح
أعلنت شركة OpenAI عن معيار BrowseComp، وهو عبارة عن مجموعة من 1266 مهمة بحثية تهدف إلى قياس قدرة وكلاء الذكاء الاصطناعي على التنقل عبر صفحات الويب من أجل إيجاد معلومات معقدة ودقيقة.
مميزات BrowseComp:
- يتكون من 1266 مهمة بحثية بإجابات قصيرة وواضحة
- يركز على الاستدلال متعدد الخطوات والتصفح الديناميكي
- تم إنشاؤه باستخدام منهجية “السؤال العكسي” لجعل البحث أكثر تحديًا
- يغطي مجالات متعددة: العلوم، التاريخ، الفنون، الرياضة، الترفيه
- يمنع الحلول السطحية ويعتمد على التحليل العميق وتصفية الضجيج المعلوماتي
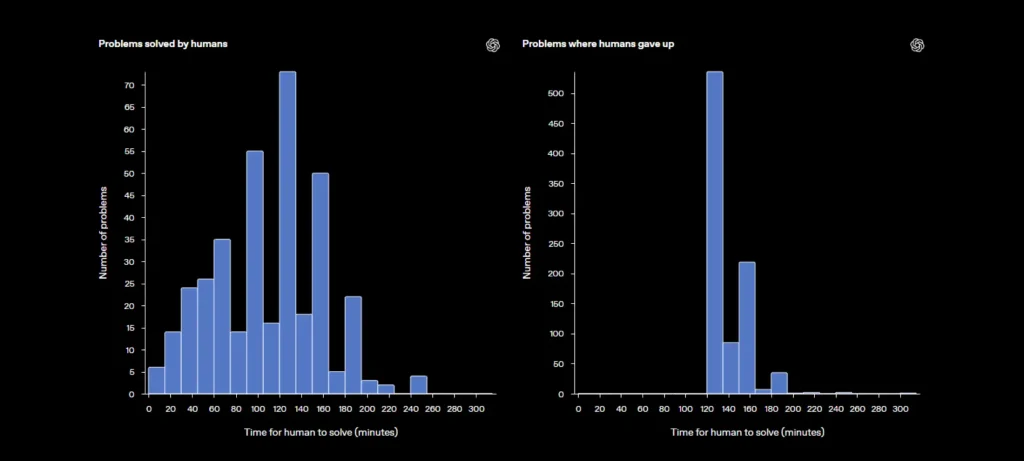
- تم التحقق من صعوبة المهام من خلال مدربين بشريين لم يستطيعوا حل 71% منها خلال ساعتين
نتائج التقييم لأشهر النماذج:
- GPT-4o بدون تصفح: 0.6% دقة فقط
- GPT-4o مع التصفح: 1.9%
- GPT-4.5: نتائج مشابهة
- OpenAI o1: 9.9% بفضل قدراته على الاستدلال
- نموذج Deep Research: الأفضل أداءً بـ 51.5% دقة، ويتميز بالبحث التكراري وتحليل الأدلة
الأهداف المستقبلية لـ BrowseComp
يأتي هذا المعيار من OpenAI لتحقيق عدة أهداف:
- نقل التقييم من الحفظ إلى البحث والتفكير التحليلي
- تطوير وكلاء ذكاء اصطناعي قادرين على التعامل مع سيناريوهات العالم الحقيقي
- بناء نماذج تعتمد على التصفح الديناميكي والملاحة الذكية متعددة الخطوات
- تحسين استراتيجيات البحث وتحليل الثقة في النتائج الناتجة عن النماذج
- تشجيع المجتمع البحثي على تطوير وكلاء AI أكثر كفاءة في جمع المعلومات المعقدة
يُمثل BrowseComp خطوة جريئة نحو تقييم فعلي لقدرات الذكاء الاصطناعي في مهام العالم الواقعي. ورغم التحديات، أظهر نموذج Deep Research بوادر واعدة لمستقبل أفضل في مجال تصفح الويب الذكي.





