

هل تُعطي منصة LMArena الأفضلية للعمالقة؟ تقرير مثير للجدل
أثار تقرير بحثي جديد جدلًا واسعًا حول نزاهة LMArena، المنصة الشهيرة لتقييم نماذج الذكاء الاصطناعي، متهمًا إياها بالتحيّز لصالح عمالقة التكنولوجيا.
تفاصيل الخبر
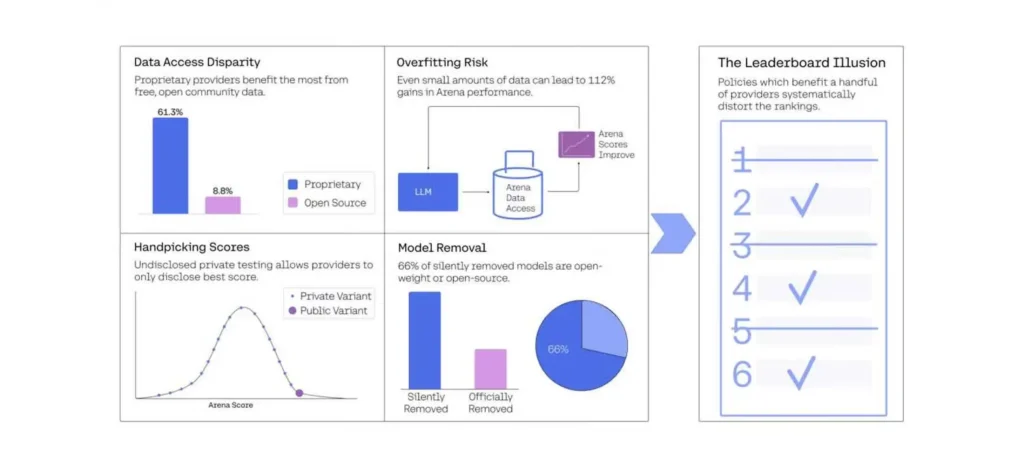
كشف باحثون من Cohere Labs ومعاهد مرموقة مثل MIT وStanford عن مشكلات منهجية في تقييمات منصة LMArena:
- تحايل محتمل من الشركات الكبرى: مثل Meta وGoogle وOpenAI يُقال إنها تختبر سرًا نسخًا متعددة من نماذجها وتنشر فقط النتائج الأفضل.
- تمييز في تكرار العينات: تم تسجيل أن نماذج Google وOpenAI حصلت على أكثر من 60% من تفاعلات المستخدمين، مقارنة بنماذج مفتوحة المصدر.
- إمكانية التخصيص المفرط: الدراسة أظهرت أن مجرد الوصول إلى بيانات Arena يساعد على تحسين الأداء في اختبارات Arena نفسها، مما يشير إلى تحسين موجه للمنصة وليس للقدرات الفعلية.
- اختفاء غير معلن للنماذج: تم سحب 205 نموذجًا من المنصة بهدوء، وكانت النسبة الأكبر منها من النماذج مفتوحة المصدر.
الأهداف المستقبلية
في ضوء هذه الادعاءات، يرى الباحثون ضرورة اتخاذ خطوات لضمان العدالة والشفافية في منصات التقييم:
- المطالبة بالشفافية: توضيح آلية عرض النماذج وترتيبها على LMArena.
- مراجعة خوارزميات التقييم: لتصبح النتائج أكثر تمثيلًا للأداء الفعلي للنماذج.
- دعم النماذج مفتوحة المصدر: للحد من التحيز وتشجيع الابتكار من جهات غير ربحية.
- بناء أدوات تقييم بديلة: تعتمد على المجتمع وتحد من هيمنة الشركات الكبرى.
الجدل الدائر حول LMArena يُظهر أن تقييم الذكاء الاصطناعي لا يقل تعقيدًا عن تطويره، ويتطلب التزامًا مشتركًا بالنزاهة والشفافية.





