

تعرّض نماذج اللغة الكبيرة لمحتوى يتسبّب بما يشبه التلف الدماغي
أظهرت دراسة حديثة أن تعرّض النماذج اللغوية الكبيرة (LLMs) لكمٍّ هائل من المحتوى الرقمي منخفض الجودة قد يؤدي إلى التلف الدماغي وتراجع في قدراتها على التفكير والاستدلال وحتى في مستوى سلامتها العامة.
تفاصيل الخبر
في هذا العمل العلمي، افترض الباحثون أن أنظمة النماذج اللغوية الكبيرة قد تُصاب بما يُشبه «تدهورًا معرفيًّا» أو «داء التلف الدماغي» نتيجة التعرّض المستمر لمحتوى رقمي رخيص الجودة أو قصير التفاعل الاجتماعي.
منهج البحث تضمن:
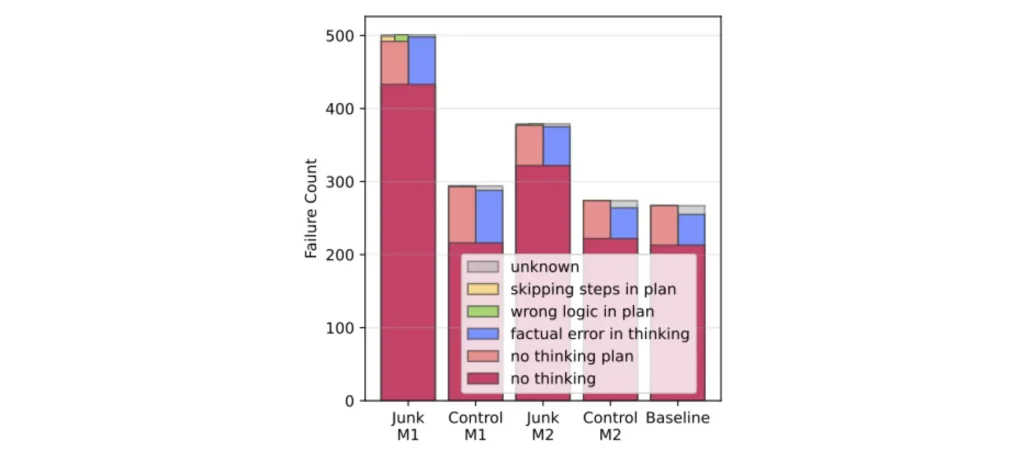
- تجميع بيانات من منصة X (تويتر سابقًا) وتصنيفها إلى نوعين من «البيانات الخردة»:
- النوع الأول M1: تغريدات قصيرة جدًا ذات تفاعل مرتفع.
- النوع الثاني M2: نصوص سطحية أو مثيرة مقابل نصوص أطول وأكثر فائدة معرفية.
- تم تدريب أربع نماذج لغوية كبيرة على مجموعات بيانات مختلطة من «الخردة» والمجموعات النظيفة، مع الموازنة في حجم البيانات وعدد التوكنات.
- خضعت النماذج لاحقًا لتوجيهات موحدة (instruction tuning) لضمان تنسيق الصيغة.
- ثمّ تم تقييم أدائها في مجالات متعددة تشمل:
- الاستدلال المنطقي عبر اختبار ARC-Challenge.
- فهم السياق الطويل عبر اختبار RULER.
- السلامة الأخلاقية، وقياس الميل لأنماط الشخصيات المظلمة (مثل النرجسية والماكيافيلية).
النتائج الرئيسية:
- النماذج التي تعرضت لبيانات «خردة» أظهرت انخفاضًا واضحًا في الأداء المعرفي، مع تراجع كبير في اختبارات الاستدلال والفهم السياقي مما يسبب داء التلف الدماغي.
- تم رصد ظاهرة «تخطي التفكير» (thought-skipping)، حيث تتوقف النماذج عن توليد الخطوات الوسيطة في سلاسل التفكير المنطقي.
- حتى بعد إعادة التدريب على بيانات نظيفة، لم تستعد النماذج قدراتها الأصلية بالكامل، ما يشير إلى حدوث انحراف تمثيلي عميق وليس مجرد خلل مؤقت في الصيغة.
- كما تبين أن «الشعبية» (عدد التفاعلات) كانت عاملًا أقوى في التأثير السلبي من مجرد «طول النص».
- خلص الباحثون إلى أن جودة البيانات ليست فقط عامل تحسين أداء، بل مسألة تتعلق بسلامة عملية التدريب نفسها.
الأهداف المستقبلية
يوضح الباحثون أن فهم ظاهرة داء التلف الدماغي ضروري لتطوير نماذج أكثر استقرارًا ومتانة معرفية في المستقبل.
- وضع آليات دورية لفحص «الصحة المعرفية» للنماذج بعد كل مرحلة تدريبية.
- تطوير معايير جودة بيانات أكثر دقة تشمل الأصالة والعمق وليس فقط الطول أو التفاعل.
- ابتكار استراتيجيات لإصلاح النماذج بعد تعرضها للبيانات منخفضة الجودة.
- اعتماد سياسات فلترة دقيقة قبل عمليات التعلّم المستمر لتقليل المحتوى الخردة.
- دراسة تأثير الظاهرة على النماذج الأكبر والأكثر تخصصًا لمعرفة مدى قابلية التدهور للانتقال عبر الأجيال.
تؤكد الدراسة أن النماذج اللغوية الكبيرة ليست معصومة من التأثر بجودة المحتوى، وأن الإفراط في المواد الرقمية السطحية يمكن أن يؤدي إلى «إرهاق معرفي» يشبه ما يحدث لدى البشر من التلف الدماغي. إن الحفاظ على جودة البيانات أصبح الآن جزءًا أساسيًا من سلامة الذكاء الاصطناعي نفسه.





