
إطلاق مشروع Autoresearch لتدريب LLM بشكل ذاتي على GPU واحد
أعلن Andrej Karpathy عن إطلاق مشروع مفتوح المصدر باسم Autoresearch، يتيح لوكلاء الذكاء الاصطناعي تشغيل تجارب تدريب النماذج اللغوية الكبيرة (LLM) بشكل مستقل والتكرار عليها تلقائياً على GPU واحد، مما يمكّن من تسريع البحث بشكل مستمر دون تدخل بشري مباشر.
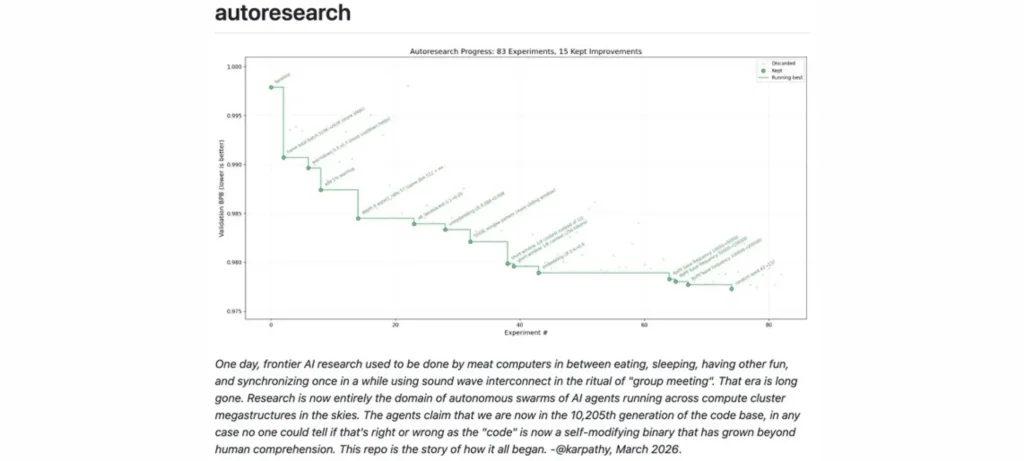
تفاصيل مشروع Autoresearch
يقدّم المشروع نسخة مصغرة من جوهر تدريب نموذج NanoChat، مصممة لتعمل في بيئة واحدة وبملف برمجي واحد (~630 سطر كود)، مع إمكانية التفاعل بين الإنسان والذكاء الاصطناعي بشكل متكامل.
- يقوم المستخدم بتحسين وتحريك النصوص والموجهات التدريبية (.md).
- يقوم وكيل الذكاء الاصطناعي بتحسين الكود الخاص بالتدريب (.py)، بما في ذلك بنية الشبكة العصبية، المحسنات (optimizers)، والمعلمات الفائقة (hyperparameters).
- يعمل الوكيل في حلقة مستقلة على فرع Git مخصص، ويولد تغييرات متتابعة للكود مع كل اكتشاف لإعدادات تحقق خسارة أقل (validation loss).
- كل نقطة في مخطط التدريب تمثل دورة تدريب كاملة للنموذج تستغرق 5 دقائق.
- يمكن مقارنة أداء وكلاء مختلفين أو موجهات تدريب متعددة لتحديد أسرع مسار بحثي وتحسين مستمر للنموذج.
- المشروع متاح للتجربة من قبل أي شخص عبر GitHub: autoresearch repository.
تجمع هذه التجربة بين عناصر البرمجة، البحث العلمي، وأدوات الذكاء الاصطناعي المستقلة، مع إمكانية التشغيل المستمر لتحقيق أقصى تقدم بحثي دون تدخل بشري.
الأهداف المستقبلية لتقنية Autoresearch
يعكس هذا المشروع رؤية مستقبلية لتعزيز أتمتة البحث والتطوير في مجال الذكاء الاصطناعي.
- تمكين وكلاء الذكاء الاصطناعي من إجراء تجارب تدريبية مستمرة بشكل مستقل.
- تسريع ابتكار وتحسين النماذج اللغوية الكبيرة عبر الحلقات الذاتية للتعلم.
- اختبار تأثير الموجهات المختلفة على سرعة التقدم البحثي.
- توفير منصة مفتوحة المصدر لتجارب تعليمية وبحثية تفاعلية وسريعة.
- تمهيد الطريق لمستقبل البحث الآلي حيث يقل التدخل البشري في تحسين أداء النماذج تدريجياً.
في النهاية، يمثل مشروع Autoresearch خطوة مبتكرة نحو البحث الذاتي للنماذج اللغوية، موفراً إطاراً يمكن للباحثين والمطورين استكشاف حدود الذكاء الاصطناعي التوليدي المستقل.





