

إطلاق HunyuanOCR من Tencent: نموذج بصري متطور لفهم المستندات
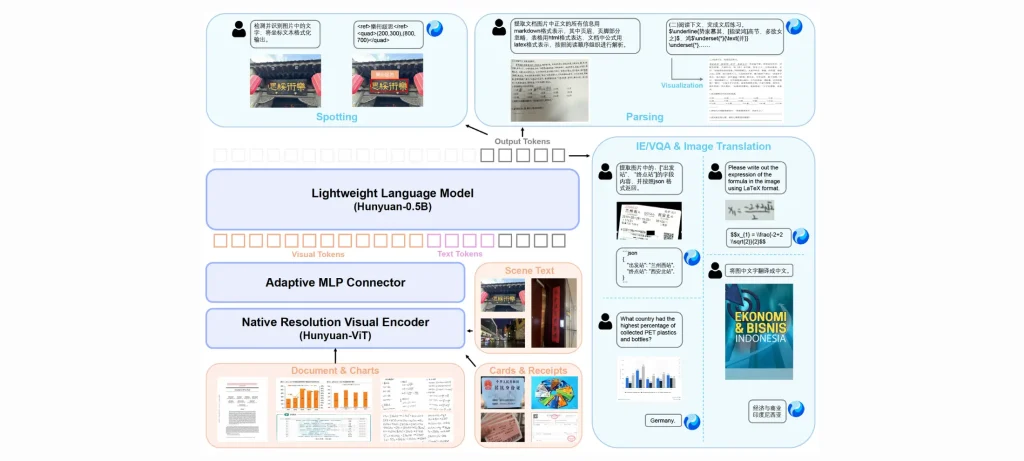
يقدّم HunyuanOCR من Tencent نموذجًا بصريًا خفيفًا ومتطورًا لمعالجة المستندات واستخراج المعلومات بدقة عالية، مع دعم شامل للغات وبنية فعّالة تناسب التطبيقات الحديثة.
تفاصيل الخبر
هذا الإصدار المفتوح يضع HunyuanOCR ضمن أقوى النماذج البصرية لفهم النصوص المتقدمة ومعالجة المستندات.
- يعتمد على بنية متعددة الوسائط بوزن 1 مليار باراميتر فقط.
- يحقق أرقامًا متقدمة في مهام التعرف على النصوص واكتشافها.
- يتعامل مع المستندات المعقدة متعددة اللغات بسلاسة كبيرة.
- يدمج مهام الكشف والقراءة والاستخراج ضمن نموذج واحد دون الحاجة إلى أنظمة متسلسلة معقدة.
- يقدم أداءً عاليًا في استخراج الترجمة من الصور والترجمات من مقاطع الفيديو.
- يسمح بتنفيذ مهمة كاملة بتعليم واحد ونتيجة واحدة مما يقلل التكاليف التشغيلية.
- يدعم أكثر من 100 لغة ويعمل بكفاءة في النصوص المختلطة.
- يوفّر نشرًا سريعًا عبر vLLM مع متطلبات عتاد معقولة.
الأهداف المستقبلية
تهدف تينسنت إلى تعزيز قدرات HunyuanOCR وتطويره ليصبح أكثر ذكاءً وشمولية.
- تحسين أداء النموذج داخل مكتبة Transformers وتقليل الفجوة مع vLLM.
- تعزيز قدرات استخراج المعلومات من المستندات المعقدة والفواتير والعقود.
- توسيع نطاق اللغات المدعومة وتحسين جودة القراءة في النصوص منخفضة الدقة.
- تطوير أدوات تكميلية تساعد المطورين على بناء حلول OCR أسهل وأكثر تكاملاً.
يمثل HunyuanOCR خطوة قوية في عالم النماذج البصرية، إذ يجمع بين الخفة والقوة والدقة، مما يجعله خيارًا مميزًا للتطبيقات المتقدمة في فهم المستندات.





